This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
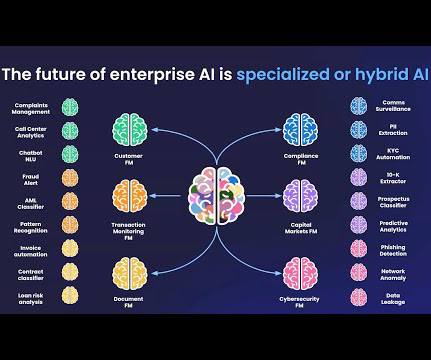
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and data preparation activities.
Looking back ¶ When we started DrivenData in 2014, the application of datascience for social good was in its infancy. There was rapidly growing demand for datascience skills at companies like Netflix and Amazon. Weve run 75+ datascience competitions awarding more than $4.7
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. These datascience teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage.
This explains why pressure on DataScience teams is growing every day. Can I put all my data into one project without over-engineering? A concrete example is when data scientists are given some data and tasked to surface business insights and help guide the next decisioning steps. Introducing Multimodal Clustering.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is open-source, so it is free to use and modify.
By mapping content to a high-dimensional space, related pieces cluster together. Building Your Own Multimodal Search withMilvus At the webinar, attendees were treated to a practical demo of how to build a multimodal RAG systemusing: Milvus: The industrys most widely used open-source vector database.
Use DataRobot’s AutoML and AutoTS to tackle various datascience problems such as classification, forecasting, and regression. Not sure where to start with your massive trove of text data? Watch a demo recording , access documentation , and contact our team to request a demo. Request a Demo.
Load CSV data using LangChain CSV loader LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment. Creating vectorstore For this demonstration, we are going to use FAISS vectorstore.
LOAD CSV DATA USING LANGCHAIN CSV LOADER LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment. CREATING VECTORSTORE For this demonstration, we are going to use FAISS vectorstore.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Enter a stack name, such as Demo-Redshift. You should see a new CloudFormation stack with the name Demo-Redshift being created. yaml locally.
Solution overview For this demo, we use the SageMaker controller to deploy a copy of the Dolly v2 7B model and a copy of the FLAN-T5 XXL model from the Hugging Face Model Hub on a SageMaker real-time endpoint using the new inference capabilities. Now you also can use them with SageMaker Operators for Kubernetes. or above installed.
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft DataScience Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization.
The week was filled with engaging sessions on top topics in datascience, innovation in AI, and smiling faces that we haven’t seen in a while. Expo Hall ODSC events are more than just datascience training and networking events. We’re a few weeks removed from ODSC Europe 2023 and we couldn’t have left on a better note.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
Solution overview The web application is built on Streamlit , an open-source Python library that makes it easy to create and share beautiful, custom web apps for ML and datascience. Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines.
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data. EMA Technical Case Study, sponsored by Ahana.
In several earlier blog posts, we have focused on what we at DataRobot call the AI production gap , which refers to the gap that makes it difficult to transition models from the datascience teams who develop them to the IT and DevOps teams who are responsible for deploying and monitoring them in production. Request a Demo.
You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data. You encounter bottlenecks because you need to rely on data engineering and datascience teams to accomplish these goals.
Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (DataScience) kernel to run the sample code. For demo purposes, we use approximately 1,600 products. We use the first metadata file in this demo. We use a pretrained ResNet-50 (RN50) model in this demo.
To understand how DataRobot AI Cloud and Big Query can align, let’s explore how DataRobot AI Cloud Time Series capabilities help enterprises with three specific areas: segmented modeling, clustering, and explainability. Flexible BigQuery Data Ingestion to Fuel Time Series Forecasting. Enable Granular Forecasts with Clustering.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Databricks Databricks is the developer of Delta Lake, an open-source project that brings reliability to data lakes for machine learning and other cases. Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks.
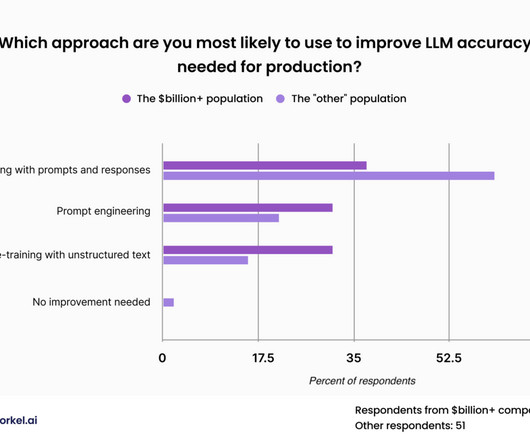
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. Data scientists can clean this up ahead of pre-training in a number of ways.
The demo implementation code is available in the following GitHub repo. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in datascience and independent consulting in AI/ML. Dr. Changsha Ma is an AI/ML Specialist at AWS.
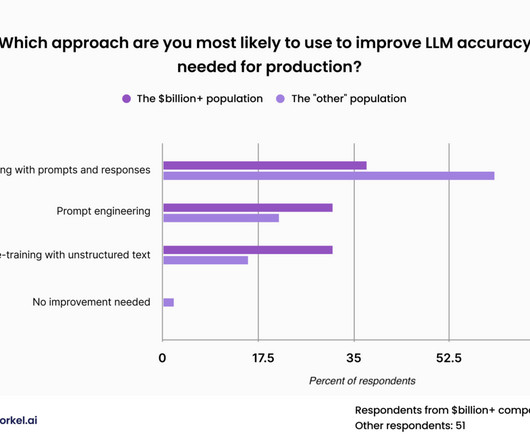
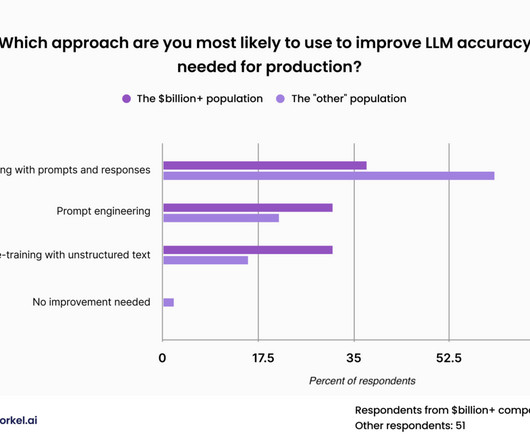
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right data prepared in the right way.
Moreover, you will also learn the use of clustering and dimensionality reduction algorithms. This course is useful for Data Scientists who are keen to expand their expertise in ML. Skill Level – Anyone who wants to learn Machine Learning Course Content Feature Selection How does a model learn? Thus, simplifying your learning curve.
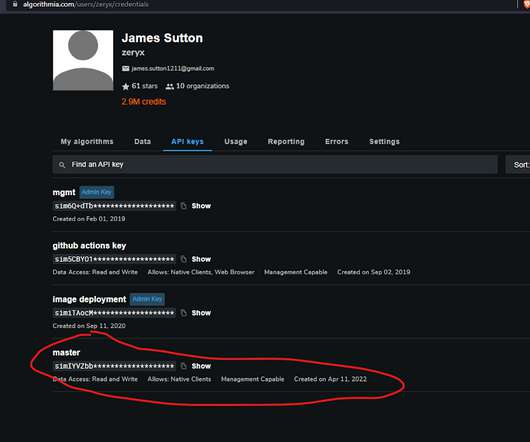
DataScience Expertise Meets Scalability. The Demo: Autoscaling with MLOps. In this demo, we are completely unattended. If you want to take this demo and rip out a few parts to incorporate into your production code, you’re free to do so. Admin keys are not required for this demo.
Today’s most cutting-edge Generative AI and LLM applications are all trained using large clusters of GPU-accelerated hardware. At Snowflake Summit, NVIDIA is showing demos of its NeMo platform to show the power of these new capabilities within Snowflake. What Does This Mean for Enterprise DataScience and ML Teams?
I realized that the algorithm assumes that we like a particular genre and artist and groups us into these clusters, not letting us discover and experience new music. You can check a live demo of the app using the link below: Spotify Reccomendation BECOME a WRITER at MLearning.ai // invisible ML // 800+ AI tools Mlearning.ai
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. Data scientists can clean this up ahead of pre-training in a number of ways.
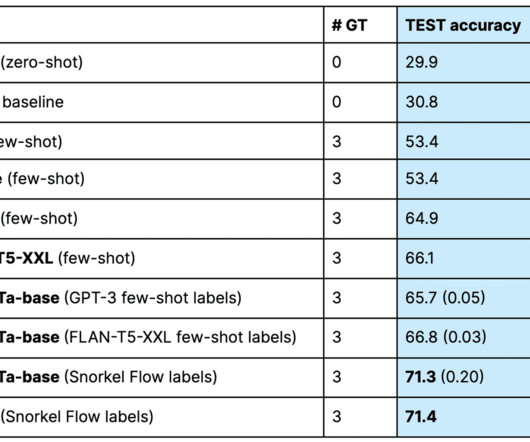
I recently talked with Matt Casey, datascience content lead at Snorkel AI, about this case. Snorkel Flow’s programmatic labeling process starts with labeling functions—essentially programmable rules to label data. See what Snorkel can do to accelerate your datascience and machine learning teams.
This keynote will also include a live demo of transfer learning and deployment of a transformer model using Hugging Face and MLRun; showcasing how to make the whole process efficient, effective, and collaborative. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Corporate leaders soon urged datascience teams to use large language models (LLMs), and datascience teams turned to fine-tuning and retrieval-augmented generation (RAG) to mitigate generative AI (genAI) shortcomings. Professionals in the datascience space often debate which approach yields the best result.
With Dr. Jon Krohn you’ll also get hands-on code demos in Jupyter notebooks and strategic advice for overcoming common pitfalls. Join us and you’ll also get a hands-on example of a personalized search using the open-source Weaviate engine which covers the details of Collaborative Filtering, HDBSCAN clustering, and Graph Neural Networks.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right data prepared in the right way.
I recently talked with Matt Casey, datascience content lead at Snorkel AI, about this case. Snorkel Flow’s programmatic labeling process starts with labeling functions—essentially programmable rules to label data. Book a demo today. We were ready to help. This resulted in an unusually high number of labeling functions.
This adaptability makes them versatile tools for a variety of industries, from legal document analysis to customer care (For a demo of how to fine-tune a OSS LLM, check out the github repo here ). Application: A gen AI model can be utilized to generate synthetic data, which mimics the real-world data in style and diversity.
It turned out that a better solution was to annotate data by using a clustering algorithm, in particular, I chose the popular K-means. This means that it can infer knowledge from data without a supervised signal (i.e. So I simply run the K-means on the whole dataset, partitioning it into 4 different clusters.
Team / participant Features Models Data sources NASAPalooza Paper search, paper recommendation, doc upload, paper summarization, chatbot, people search, keyword extraction, topic trends, dataset analysis GPT-3.5 His expertise and experience make him a valuable asset in the field of datascience and Generative AI.
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. Data scientists can clean this up ahead of pre-training in a number of ways.
Conclusion To get started today with SnapGPT, request a free trial of SnapLogic or request a demo of the product. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
Second, while OpenAI’s GPT-4 announcement last March demoed generating website code from a hand-drawn sketch, that capability wasn’t available until after the survey closed. Third, while roughing out the HTML and JavaScript for a simple website makes a great demo, that isn’t really the problem web designers need to solve.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content