

Traditional vs Vector databases: Your guide to make the right choice
Data Science Dojo
MARCH 8, 2024
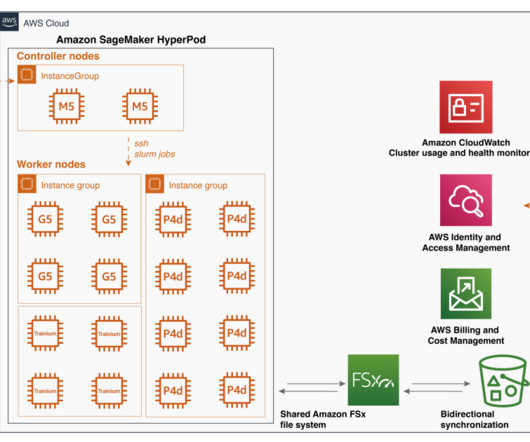
Traditional vs vector databases Data models Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.




































Let's personalize your content