This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
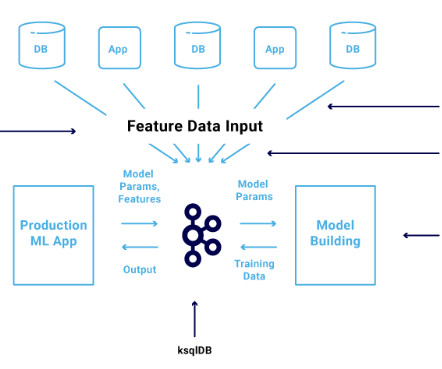
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Each component contributes to the overall goal of extracting valuable insights from data. Data collection This involves techniques for gathering relevant data from various sources, such as datalakes and warehouses. Accurate data collection is crucial as it forms the foundation for analysis.
Depending on the requirement, it is important to choose between transient and permanent tables, as well as data recovery needs and downtime considerations. Always set the minimum cluster count to 1 to prevent over-provisioning. Setting minimum cluster counts higher than one results in unused clusters that incur costs.
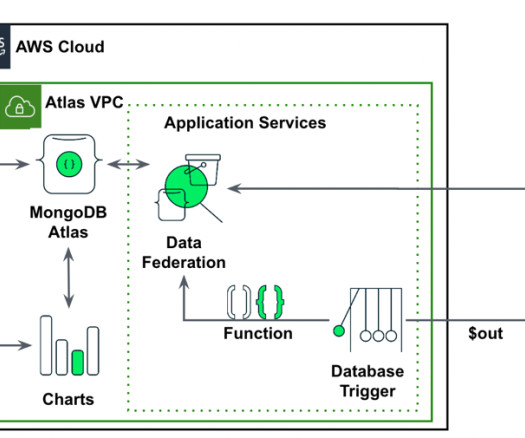
Prerequisites For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas. The following screenshots shows the setup of the data federation. Setup the Database access and Network access.
Despite the benefits of this architecture, Rocket faced challenges that limited its effectiveness: Accessibility limitations: The datalake was stored in HDFS and only accessible from the Hadoop environment, hindering integration with other data sources. This also led to a backlog of data that needed to be ingested.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster.
Expo Hall ODSC events are more than just data science training and networking events. Thank you to everyone who attended for making this event possible, and showing once again why we do what we do — connecting the greater data science community together to push the industry forward. What’s next?
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of data pipelines. Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures.
Why is Data Mining Important? Data mining is often used to build predictive models that can be used to forecast future events. Moreover, data mining techniques can also identify potential risks and vulnerabilities in a business. The gathering of data requires assessment and research from various sources.
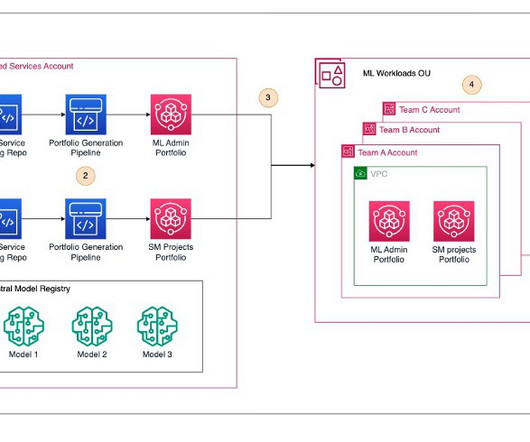
Data Governance Account This account hosts data governance services for datalake, central feature store, and fine-grained data access. The lead data scientist approves the model locally in the ML Dev Account. These resources can include SageMaker domains, Amazon Redshift clusters, and more.
You’ll cover Why standard ML systems are inherently unreliable and dangerous in finance and investing The three types of errors in all financial models and why they are endemic The paramount importance of quantifying the uncertainty of model inputs and outputs The three types of uncertainty and different approaches to quantifying them Deep flaws in (..)
Example: models: my_project: events: # materialize all models in models/events as tables +materialized: table csvs: # this is redundant, and does not need to be set +materialized: view We can also configure the materialization type inside the dbt SQL file or the yaml file. You can do this by providing either of the following.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Databricks Databricks is the developer of Delta Lake, an open-source project that brings reliability to datalakes for machine learning and other cases. Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks.
Uninterruptible Power Supply (UPS): Provides backup power in the event of a power outage, to keep the equipment running long enough to perform an orderly shutdown. Cooling systems: Data centers generate a lot of heat, so they need cooling systems to keep the temperature at a safe level. Not a cloud computer?
Data ingress and egress Snorkel enables multiple paths to bring data into and out of Snorkel Flow, including but not limited to: Upload from and download to your local computer Data connectors with common third-party datalakes such as Databricks, Snowflake, Google Big Query as well as S3, GCS, and Azure buckets.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. You can use Snowflake cloud computing to store raw data in structured or variant format, using various data models to meet the needs.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture.
The service will consume the features in real time, generate predictions in near real-time , such as in an event processing pipeline, and write the outputs to a prediction queue. Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on.
When I was at Ford, we needed to hook things up to the car and telemetry it out and download all that data somewhere and make a datalake and hire a team of people to sort that data and make it usable; the blocker of doing any ML was changing cars and building datalakes and things like that.
To get started, it is my pleasure to introduce you to our guest, machine learning and data science engineer Kuba Cieslik. It’s nice to participate in this event. In the end, this is a process of creating a datalake but for images that you can. Welcome, Kuba. Kuba: Sure. Hello, everyone.
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a DataLake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content