

Unleashing the power of Presto: The Uber case study
IBM Journey to AI blog
SEPTEMBER 25, 2023
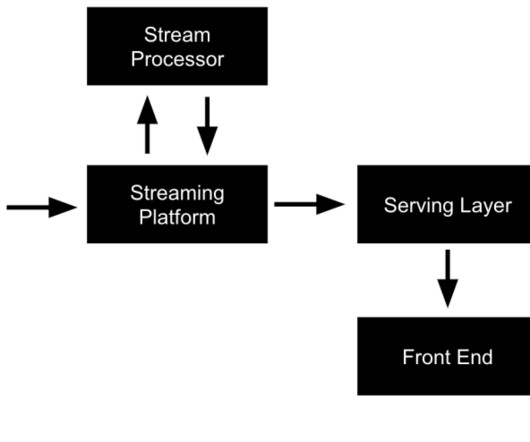
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data.


















Let's personalize your content