This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
inherits tags on the cluster definition, while serverless adheres to Serverless Budget Policies ( AWS | Azure | GCP ). Case 2: Only one task runs on serverless In this case, BP tags would also propagate to system tables for the serverless compute usage, while the classic compute billing record inherits tags from the cluster definition.
This article covers eight practical methods in BigQuery designed to do exactly that, from using AI-powered agents to serving ML models straight from a spreadsheet. Machine Learning in your Spreadsheets BQML training and prediction from a Google Sheet Many data conversations start and end in a spreadsheet.
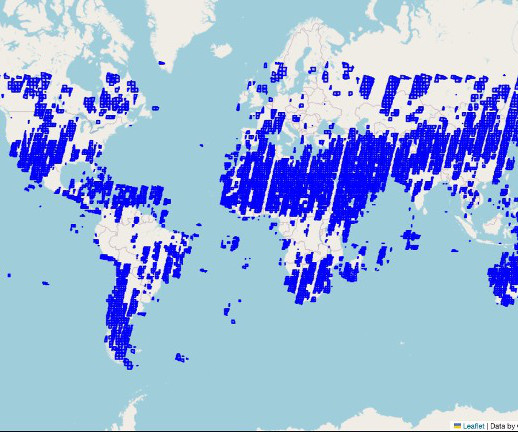
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and MLengineers to build, train, and deploy ML models using geospatial data. Identify areas of interest We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift data warehouse.
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
The new IDE for DataEngineering in Lakeflow Declarative Pipelines We also announced the General Availability of Lakeflow , Databricks’ unified solution for data ingestion, transformation, and orchestration on the Data Intelligence Platform. Preview coming soon. And in the weeks since DAIS, we’ve kept the momentum going.
Built directly on Spark’s engine, MLlib pipelines leverage: DataFrame APIs (not RDDs anymore), Declarative transformations across nodes, Automatic memory and partition management, and Built-in model tuning and evaluation tools. All of it runs natively on distributed clusters. No wrappers. But that’s the price you pay for scale.
For deployment, we containerized Open WebUI and orchestrated it on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, using automatic scaling to dynamically adjust resources based on demand while maintaining high availability.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This created a challenge for data scientists to become productive.
On a lightweight four-node cluster, the TTR and TTS analyses completed in 5 and 40 minutes respectively on the network described above (1,700 nodes)—all for under $10 in cloud spend. This highlights the solution’s impressive speed and cost-effectiveness.
If you are an aspiring data scientist, or working professional looking to better understand this critical step in the ML Lifecycle, a Machine Learning Course could provide you the foundation and practical experience to avoid these problems. Why Model Deployment Matters in Machine Learning? Here’s how: 1. Here’s how: 1.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a dataengineering team as one of the first engineers. We were focused on building data pipelines and models to protect our users from malicious phonecalls.
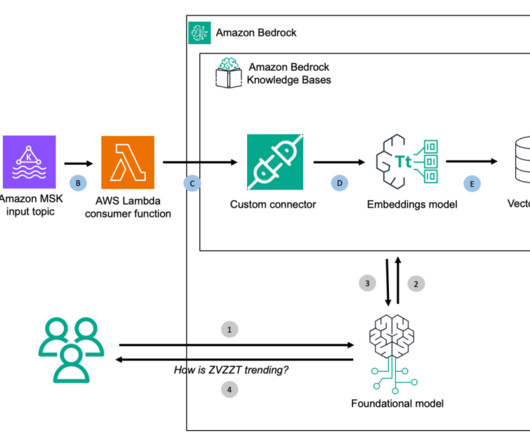
The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic. Prepare the test data. Define a Python function to put data to the topic.
As organizations increasingly deploy foundation models (FMs) and other machine learning (ML) models to production, they face challenges related to resource utilization, cost-efficiency, and maintaining high availability during updates. Li held data science roles in the financial and retail industries.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. You must be independent and self-organized. I wonder if we can move away from representation purely on where you live.
reply ml- 1 day ago | prev | next [–] Still on my sabbatical and continuing to build on things I enjoy rather than things that pay (for now). reply ml- 18 hours ago | root | parent | next [–] Appreciate it! ML runs locally, no clouds, uploads etc. It was incredibly useful to me, thanks! Really cool idea.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It provides a large cluster of clusters on a single machine.
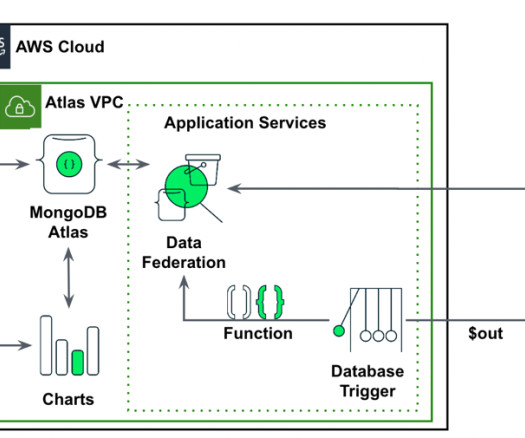
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
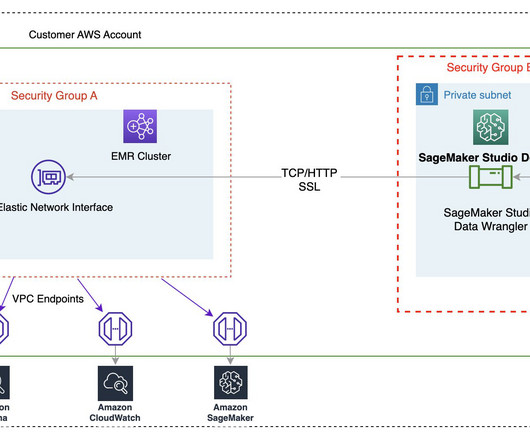
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
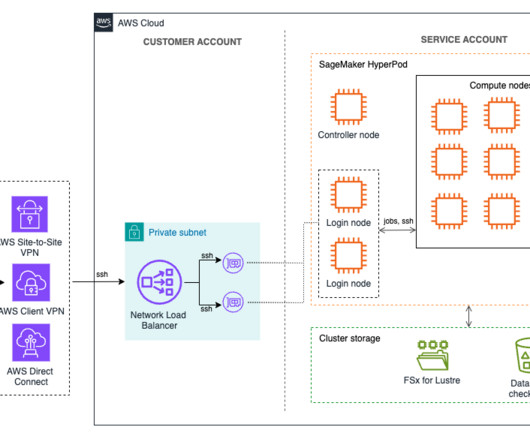
Amazon SageMaker HyperPod is designed to support large-scale machine learning (ML) operations, providing a robust environment for training foundation models (FMs) over extended periods. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. We recently developed four more new models.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML.
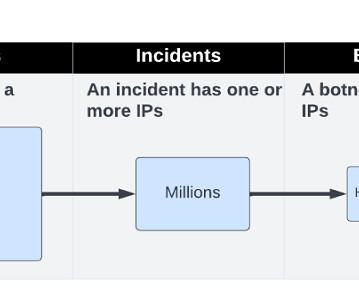
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. ML Governance: A Lean Approach Ryan Dawson | Principal DataEngineer | Thoughtworks Meissane Chami | Senior MLEngineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance.
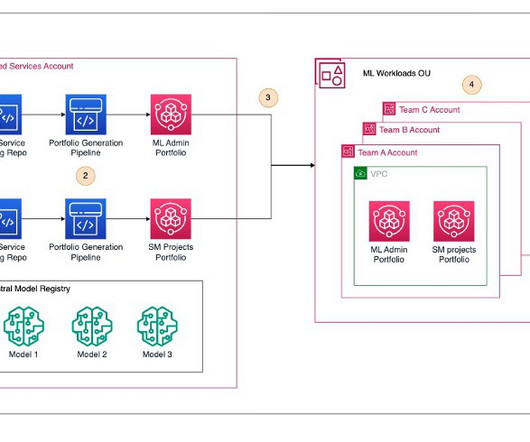
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Data scientists and dataengineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Import data page, for Data Source , choose DocumentDB and Add Connection.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























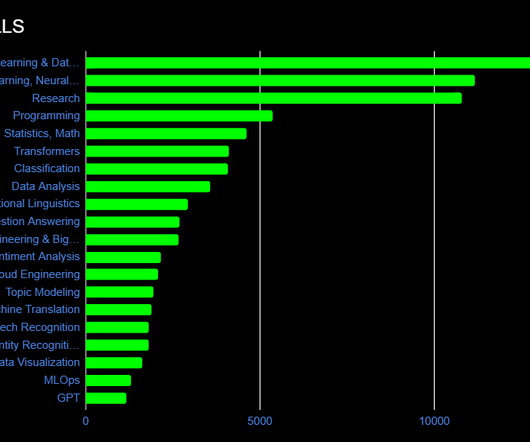
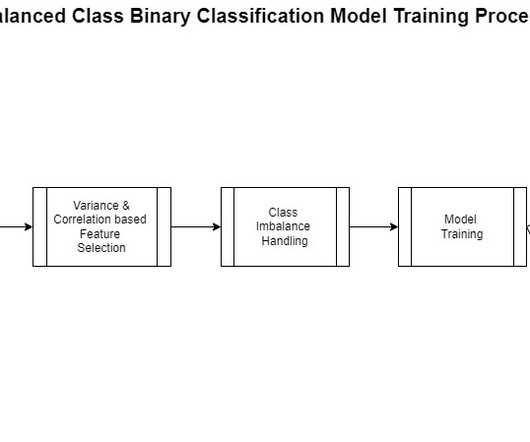
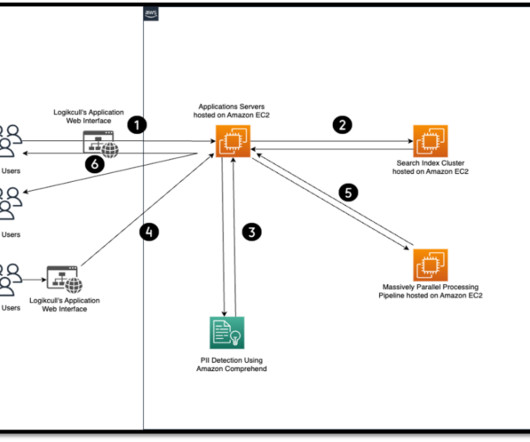






Let's personalize your content