

Speed up your cluster procurement time with Amazon SageMaker HyperPod training plans
AWS Machine Learning Blog
DECEMBER 5, 2024
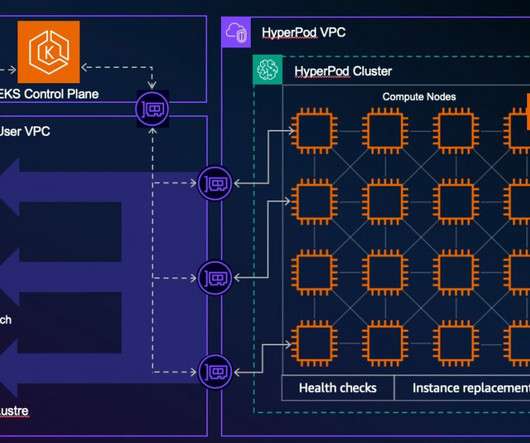
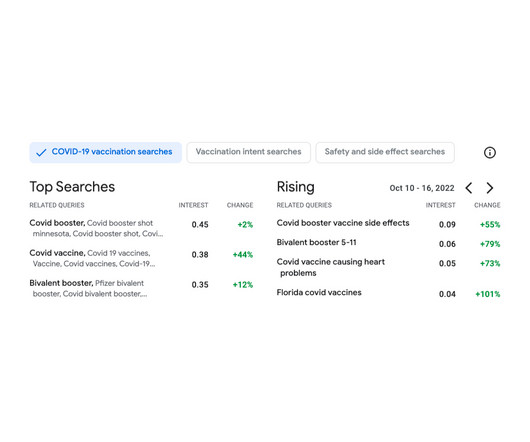
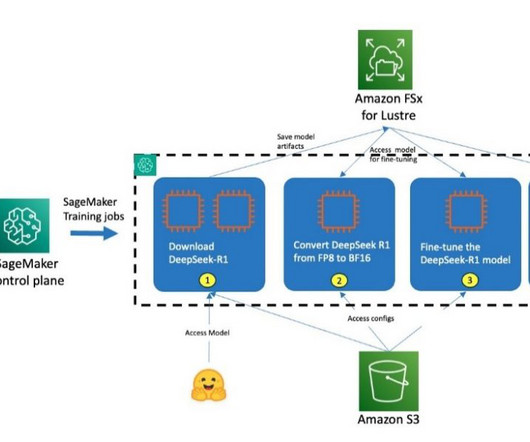
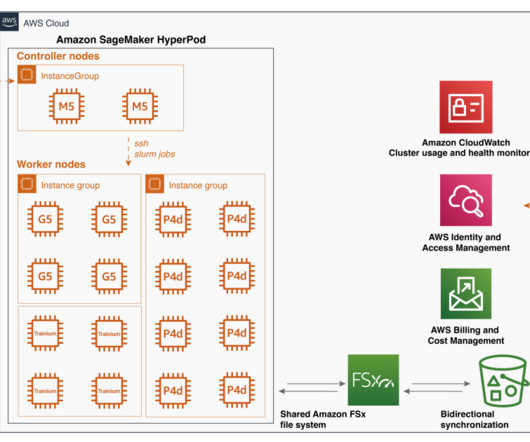
However, customizing these larger models requires access to the latest and accelerated compute resources. In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. For Target , select HyperPod cluster.






























Let's personalize your content