This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
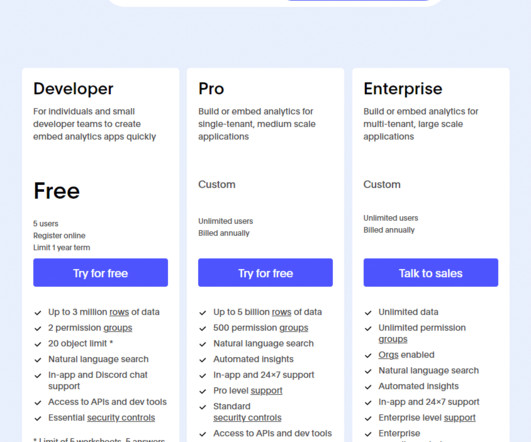
AI/BI Genie is now generally available, empowering business users to ask data questions in natural language and receive accurate, explainable answers. Powered by Data Intelligence, Genie learns from organizational usage patterns and metadata to generate SQL, charts, and summaries grounded in trusted data.
These agents follow a combination of RAG and text-to-SQL approaches. These approaches provide precise, context-aware responses while maintaining data governance. Implementation details of the text-to-SQL workflow is described in the following diagram. Access to these agents is governed by user roles and job functions.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
“ Vector Databases are completely different from your clouddata warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. This process is repeated until the entire text is divided into coherent segments. Return the chunks as an ARRAY.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance. In this blog, we will describe 10 such Python Scripts that can provide a blueprint for using the Python component efficiently in Matillion ETL for Snowflake AI DataCloud.
FeatureByte, an AI startup formed by a team of data science experts, announced the release of its open-source FeatureByte SDK. The SDK allows data scientists to use Python to create state-of-the-art features and deploy feature pipelines in minutes – all with just a few lines of code.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? using for loops in Python).
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure Data Lake. Python support has been available for a while.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Formerly known as Periscope, Sisense is a business intelligence tool ideal for clouddata teams. With this tool, analysts are able to visualize complex data models in Python, SQL, and R. This highly flexible and modern SQL editor comes bundled with an easy-to-use, attractive interface.
The common skills required within each are listed as follows: Computer Science Programming Skills : Proficiency in various programming languages such as Python, Java, and C++ is essential. Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions.
The common skills required within each are listed as follows: Computer Science Programming Skills : Proficiency in various programming languages such as Python, Java, and C++ is essential. Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
Matillion Jobs are an important part of the modern data stack because we can create lightweight, low-code ETL/ELT processes using a GUI, reverse ETL (loading data back into application databases), LLM usage features, and store and transform data in multiple clouddata warehouses. Below are the best practices.
The Snowflake DataCloud was built natively for the cloud. When we think about clouddata transformations, one crucial building block is User Defined Functions (UDFs). Python Enabling a development team to use third-party packages can significantly reduce the need to reinvent the wheel.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
It was my first job as a data analyst. It helped me to become familiar with popular tools such as Excel and SQL and to develop my analytical thinking. The time I spent at Renault helped me realize that data analytics is something I would be interested in pursuing as a full-time career.
Services such as the Snowflake DataCloud can house massive amounts of data and allows users to write queries to rapidly transform raw data into reports and further analyses. For somebody who cannot access their database directly or who lacks expert-level skills in SQL, this provides a significant advantage.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
Proper data preparation leads to better model performance and more accurate predictions. SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. SageMaker Canvas recently added a Chat with data option. On the Create menu, choose Document.
Open source big data tools like Hadoop were experimented with – these could land data into a repository first before transformation. Thus, the early data lakes began following more of the EL-style flow. But then, in the 2010s, clouddata warehouses, particularly ones like Snowflake , came along and really changed the game.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. And once again, for loading data, do not use SQL Inserts.
There are many frameworks for testing software, but the right way to test the data and SQL scripts that change data are less obvious. This is because databases and the data therein are constantly changing. To truly test the effects of a deployment, you need to have an environment with the exact data that is in Production.
Fivetran Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move supply chain data across any clouddata platform in the market.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Snowflake AI DataCloud has become a premier clouddata warehousing solution. Maybe you’re just getting started looking into a cloud solution for your organization, or maybe you’ve already got Snowflake and are wondering what features you’re missing out on. Snowflake has you covered with Cortex.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Why Use ThoughtSpot?
Matillion Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into clouddata environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI.
Celonis unterscheidet sich von den meisten anderen Tools noch dahingehend, dass es versucht, die ganze Kette des Process Minings in einer einzigen und ausschließlichen Cloud-Anwendung in einer Suite bereitzustellen. Vielleicht haben wir auch das ein Stück weit Celonis zu verdanken. Aber auch andere Prozesse für andere Geschäftsprozesse z.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




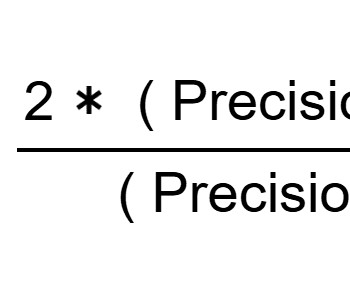


























Let's personalize your content