This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
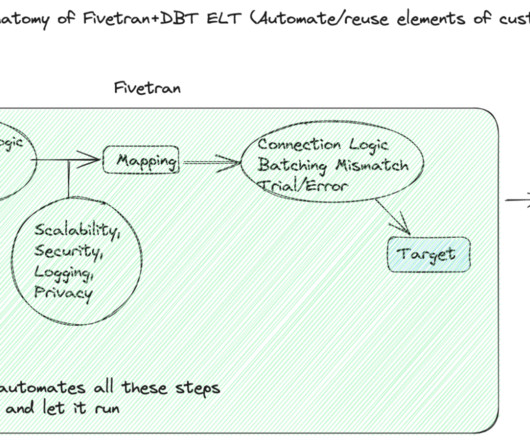
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
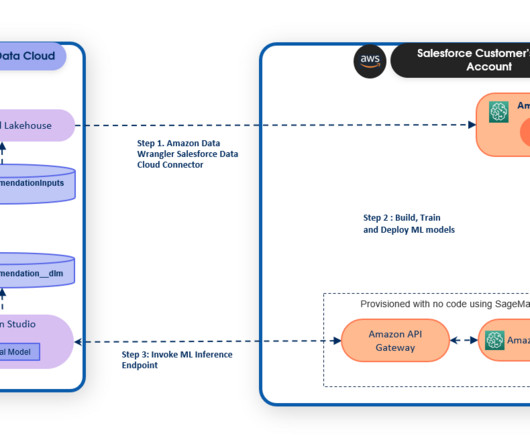
As a result, businesses can accelerate time to market while maintaining data integrity and security, and reduce the operational burden of moving data from one location to another. With Einstein Studio, a gateway to AI tools on the data platform, admins and data scientists can effortlessly create models with a few clicks or using code.
Data Cleaning and Preparation The tasks of cleaning and preparing the data take place before the analysis. This includes duplicate removal, missing value treatment, variable transformation, and normalization of data. Data Architect Designs complex databases and blueprints for data management systems.
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. Many organizations are using CDC technology to push data to clouddata platforms like Snowflake, Redshift, Databricks, and Kafka.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Watsonx.data allows customers to augment data warehouses such as Db2 Warehouse and Netezza and optimize workloads for performance and cost. IBM watsonx.ai
ThoughtSpot was designed to be low-code and easy for anyone to use across a business to generate insights and explore data. ThoughSpot can easily connect to top clouddata platforms such as Snowflake AI DataCloud , Oracle, SAP HANA, and Google BigQuery.
Why Migrate to a Modern Data Stack? With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. Legacy tools force users to manually build out processes that can be automated by the Modern Data Stack.
The people navigating these increasingly chaotic landscapes need a single place to find, understand, and use data with total confidence. Expanded Integration with Databricks Unity Catalog Unity Catalog is Databricks ’ governance and admin layer for all lakehouse data and AI assets, including files, tables, ML models, and dashboards.
This “analysis” is made possible in large part through machine learning (ML); the patterns and connections ML detects are then served to the data catalog (and other tools), which these tools leverage to make people- and machine-facing recommendations about data management and data integrations.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco. In “The modern data stack is dead, long live the modern data stack!” Cloud costs are growing prohibitive.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content