This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cross-clouddata governance with Unity Catalog supports accessing S3 data from Azure Databricks. This enables organizations to enforce consistent security, auditing, and data lineage across cloud boundaries. Lakebridge accelerates the migration of legacy datawarehouse workloads to Azure Databricks SQL.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
“ Vector Databases are completely different from your clouddatawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. This process is repeated until the entire text is divided into coherent segments. Return the chunks as an ARRAY.
One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance. In this blog, we will describe 10 such Python Scripts that can provide a blueprint for using the Python component efficiently in Matillion ETL for Snowflake AI DataCloud.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddatawarehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures?
Even with the coronavirus causing mass closures, there are still some big announcements in the clouddata science world. Google introduces Cloud AI Platform Pipelines Google Cloud now provides a way to deploy repeatable machine learning pipelines. Azure Functions now support Python 3.8 So, here is the news.
Even with the coronavirus causing mass closures, there are still some big announcements in the clouddata science world. Google introduces Cloud AI Platform Pipelines Google Cloud now provides a way to deploy repeatable machine learning pipelines. Azure Functions now support Python 3.8 So, here is the news.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure Data Lake. Python support has been available for a while. Azure Synapse.
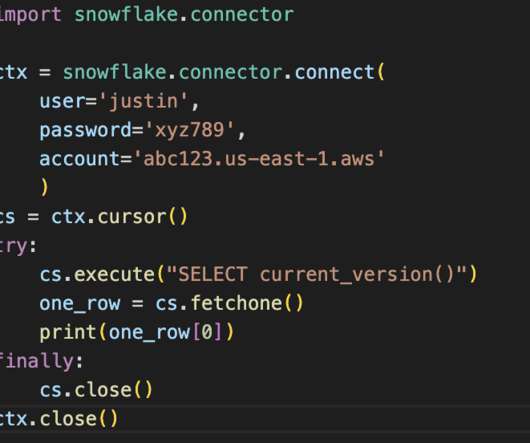
Python is the top programming language used by data engineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management. Data transformation.
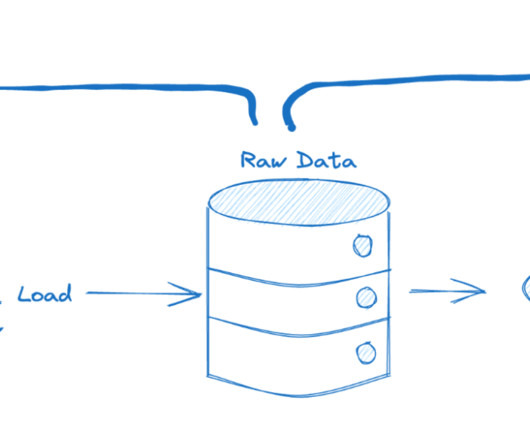
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
Amazon Redshift is the most popular clouddatawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud. Below is a sample scenario for 3 business units within an organization for the data mart layer of the datawarehouse.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
This experience helped me to improve my Python skills and get more practical experience working with big data. Another important change is that the new technologies are greatly accelerating the work with data. At Sberbank, I worked as an analyst for major B2B clients.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
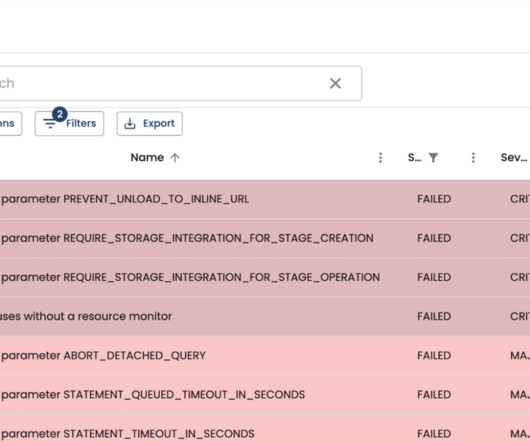
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 data lake, Snowflake clouddatawarehouse and Tableau (and how it can be fixed). Time is money,” said Leonard Kwok, Senior Data Analyst, ARC.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
Open source notebooks exist because most data science languages are a mix of object-oriented code, complex libraries, and functional programming. Plotting graphics using Python, R, Scala or other languages has always depended on conversion to JPEG format or some other graphical output that does not display when created.
Snowflake AI DataCloud has become a premier clouddata warehousing solution. Maybe you’re just getting started looking into a cloud solution for your organization, or maybe you’ve already got Snowflake and are wondering what features you’re missing out on.
Snowflake has so many features that make it the leader in the CloudDataWarehouse market. Cloning in Snowflake simply means that the data in the clone is not a copy of the original data but simply points back to the original data. Two of these tools are Terraform and phData’s own Provision tool.
Celonis versucht Machine Learning innerhalb der Plattform aus einer Hand anzubieten und hat auch eigene Python-Bibleotheken dafür entwickelt. Alternativ zu Databricks können auch andere DataWarehouse Datenbankplattformen zur Anwendung kommen, beispielsweise auch snowflake mit dbt. Bisher dreht sich hier viel eher noch um z.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content