This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? IaC allows these teams to collaborate more effectively.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. And Why did it happen?).
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Define data ownership, access controls, and data management processes to maintain the integrity and confidentiality of your data. Data integration: Integrate data from various sources into a centralized clouddata warehouse or data lake. Ensure that data is clean, consistent, and up-to-date.
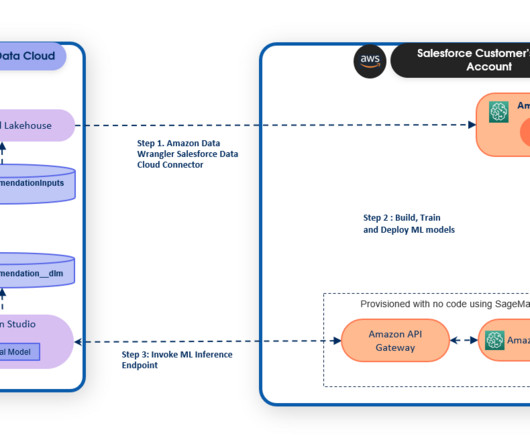
As a result, businesses can accelerate time to market while maintaining data integrity and security, and reduce the operational burden of moving data from one location to another. With Einstein Studio, a gateway to AI tools on the data platform, admins and datascientists can effortlessly create models with a few clicks or using code.
Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? A Note on the Shift from ETL to ELT.
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, datascientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
If you haven’t already, moving to the cloud can be a realistic alternative. Clouddata warehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data.
Integrating helpful metadata into user workflows gives all people, from datascientists to analysts , the context they need to use data more effectively. The Benefits and Challenges of the Modern Data Stack Why are such integrations needed? Before a data user leverages any data set, they need to be able to learn about it.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the clouddata warehouse. Jason: I’m curious to learn about your modern data stack.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
ThoughtSpot was designed to be low-code and easy for anyone to use across a business to generate insights and explore data. ThoughSpot can easily connect to top clouddata platforms such as Snowflake AI DataCloud , Oracle, SAP HANA, and Google BigQuery.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco. In “The modern data stack is dead, long live the modern data stack!” Cloud costs are growing prohibitive. Let’s dive in!
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content