This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Get a Demo Login Try Databricks Blog / Platform / Article What’s New with Azure Databricks: Unified Governance, Open Formats, and AI-Native Workloads Explore the latest Azure Databricks capabilities designed to help organizations simplify governance, modernize datapipelines, and power AI-native applications on a secure, open platform.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. Top 10 Python Scripts for use in Matillion for Snowflake 1. The default value is Python3.
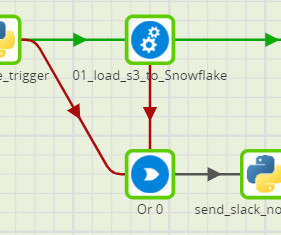
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
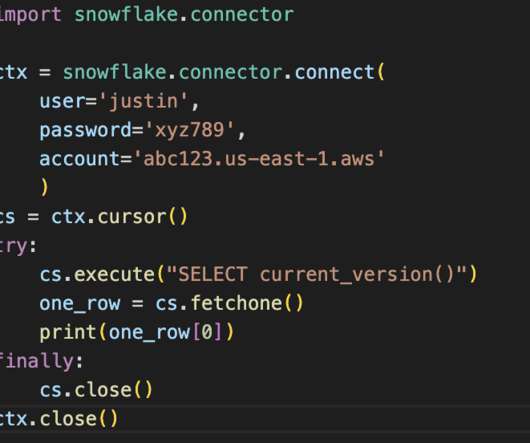
Python is the top programming language used by data engineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
Deployment with the AWS CDK The Step Functions state machine and associated infrastructure (including Lambda functions, CodeBuild projects, and Systems Manager parameters) are deployed with the AWS CDK using Python. The AWS CDK code synthesizes a CloudFormation template, which it uses to deploy all infrastructure for the solution.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices.
SageMaker has developed the distributed data parallel library , which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script. Each node has a copy of the DNN.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. You can use whatever works best for your technology.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content