This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Modern datapipeline platform provider Matillion today announced at Snowflake DataCloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. This ensures flexibility and interoperability while using the unique capabilities of each cloud provider.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Solution overview The following diagram illustrates the solution architecture for each option.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
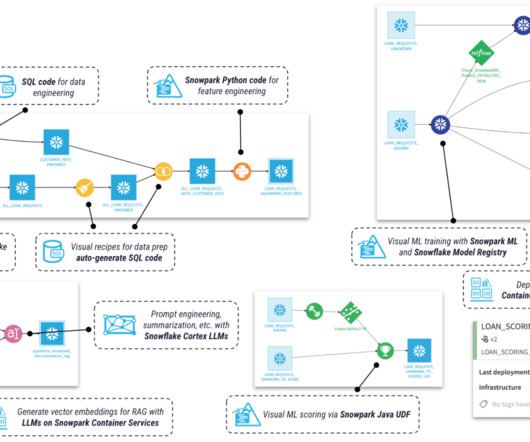
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity. Managed services like AWS Lambda and Azure Data Factory streamline datapipeline creation, while pre-built ML models in GCPs AI Hub reduce development time. Below are key strategies for achieving this.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. Xinyi Zhou is a Data Engineer at Omron Europe, bringing her expertise to the ODAP team led by Emrah Kaya.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Google BigQuery is a serverless and cost-effective multi-clouddata warehouse. Druid is specifically designed to support workflows that require fast ad-hoc analytics, concurrency, and instant data visibility are core necessities. It can also batch load files from data lakes such as Amazon S3 and HDFS. Google BigQuery.
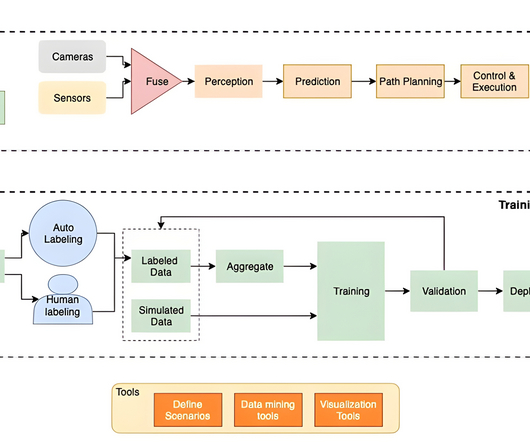
Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. Tableau’s lightning-fast Google BigQuery connector allows customers to engineer optimized datapipelines with direct connections that power business-critical reporting. Direct connection to Google BigQuery.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, clouddata ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. It’s an easy way to run analytics on IoT data to gain accurate insights.
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used.
Over time, we called the “thing” a data catalog , blending the Google-style, AI/ML-based relevancy with more Yahoo-style manual curation and wikis. Thus was born the data catalog. In our early days, “people” largely meant data analysts and business analysts. ML and DataOps teams). datapipelines) to support.
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. DataPipeline Automation. Advanced Tooling.
Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. . Tableau’s lightning-fast Google BigQuery connector allows customers to engineer optimized datapipelines with direct connections that power business-critical reporting.
Advanced analytics and AI/ML continue to be hot data trends in 2023. According to a recent IDC study, “executives openly articulate the need for their organizations to be more data-driven, to be ‘data companies,’ and to increase their enterprise intelligence.”
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI DataCloud , Fivetran, and Azure to automate invoice processing. Migrations from legacy on-prem systems to clouddata platforms like Snowflake and Redshift. This is where AI truly shines.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
Technology has been a great enabler in that quest, and most organizations recognize the value of moving to a cloud-first strategy. As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. 1 When comparing published 2023 list prices normalized for VPC hours of watsonx.data to several major clouddata warehouse vendors. IBM watsonx.ai
However, the race to the cloud has also created challenges for data users everywhere, including: Cloud migration is expensive, migrating sensitive data is risky, and navigating between on-prem sources is often confusing for users. To build effective datapipelines, they need context (or metadata) on every source.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
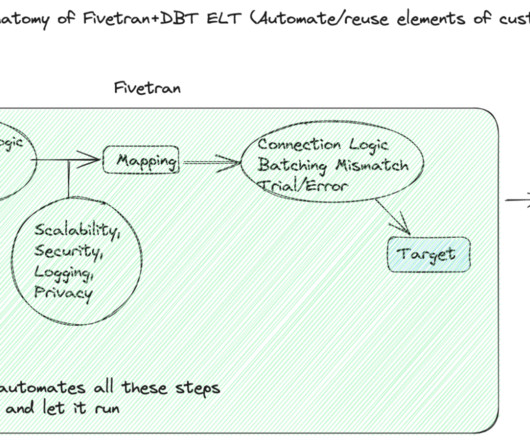
Fivetran also takes care of all the manual elements of building and maintaining a datapipeline that is not business-related so that data teams don’t have to. This is where dbt comes in – powering the transformations.
Why Migrate to a Modern Data Stack? With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. Data teams can focus on delivering higher-value data tasks with better organizational visibility.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco. In “The modern data stack is dead, long live the modern data stack!” Cloud costs are growing prohibitive.
Both persistent staging and data lakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer datapipeline. It’s not just a dumping ground for data, but a crucial step in your customer data processing workflow.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content