This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. In this session, learn about Redshift Serverless new AI-driven scaling and optimization functionality.
These developments have accelerated the adoption of hybrid-clouddata warehousing; industry analysts estimate that almost 50% 2 of enterprise data has been moved to the cloud. What is holding back the other 50% of datasets on-premises? However, a more detailed analysis is needed to make an informed decision.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Here they are in my order of importance (based upon my opinion).
Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudData warehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. A datascientist team orders a new JuMa workspace in BMW’s Catalog.
Every organization needs data to make many decisions. The data is ever-increasing, and getting the deepest analytics about their business activities requires technical tools, analysts, and datascientists to explore and gain insight from large data sets. Google BigQuery.
Define data ownership, access controls, and data management processes to maintain the integrity and confidentiality of your data. Data integration: Integrate data from various sources into a centralized clouddata warehouse or datalake.
At IBM, we believe it is time to place the power of AI in the hands of all kinds of “AI builders” — from datascientists to developers to everyday users who have never written a single line of code. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments.
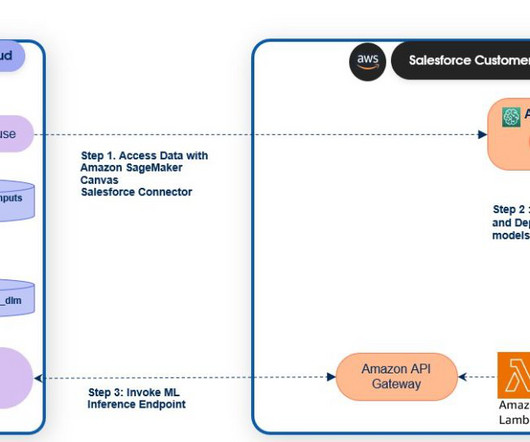
SageMaker endpoints can be registered to the Salesforce DataCloud to activate predictions in Salesforce. Salesforce DataCloud and Einstein Studio Salesforce DataCloud is a data platform that provides businesses with real-time updates of their customer data from any touch point.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
The audience grew to include datascientists (who were even more scarce and expensive) and their supporting resources (e.g., After that came data governance , privacy, and compliance staff. Power business users and other non-purely-analytic data citizens came after that. Data engineers want to catalog data pipelines.
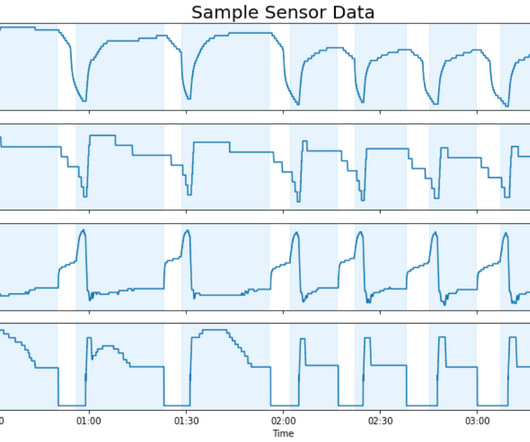
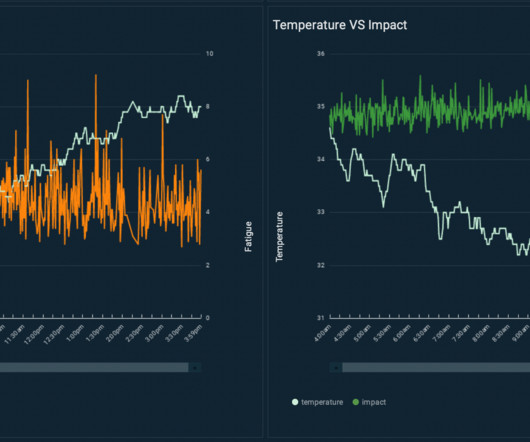
We have over 50 TB of historical equipment data and expect this data to grow quickly as more HVAC units are connected to the cloud. Data processing and model inference need to scale as our data grows. Dan Volk is a DataScientist at the AWS Generative AI Innovation Center.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data Governance and Data Security.
We have an explosion, not only in the raw amount of data, but in the types of database systems for storing it ( db-engines.com ranks over 340) and architectures for managing it (from operational datastores to datalakes to clouddata warehouses). Organizations are drowning in a deluge of data.
With more data than ever before, the ability to find the right data has become harder than ever. Yet businesses need to find data to make data-driven decisions. However, data engineers, datascientists, data stewards, and chief data officers face the challenge of finding data easily.
If you are a datascientist, manager, or executive with limited time and funds, wondering whether/how to invest in data centers and what the pros, cons, and costs would be, chances are you will start from a similar place as I — having some knowledge then looking for more, be that from humans, machines, or both.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, clouddata ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. This organization manages fleets of globally distributed edge gateways.
ETL pipeline | Source: Author These activities involve extracting data from one system, transforming it, and then processing it into another target system where it can be stored and managed. ML heavily relies on ETL pipelines as the accuracy and effectiveness of a model are directly impacted by the quality of the training data.
And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production. And it might be that these are two totally separate data environments and a lot of times they’re separate for compute processing as well.
And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production. And it might be that these are two totally separate data environments and a lot of times they’re separate for compute processing as well.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Furthermore, a shared-data approach stems from this efficient combination. What will You Attain with Snowflake?
Both persistent staging and datalakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer data pipeline. You might choose a clouddata warehouse like the Snowflake AI DataCloud or BigQuery.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content