This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cross-clouddata governance with Unity Catalog supports accessing S3 data from Azure Databricks. This enables organizations to enforce consistent security, auditing, and data lineage across cloud boundaries. Mirrored Azure Databricks Catalog is now Generally Available.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak.
Rahul Ghosh is a seasoned Data & AI Engineer with deep expertise in cloud-based data architectures, large-scale data processing, and modern AI technologies, including generative AI, LLMs, Retrieval Augmented Generation (RAG), and agent-based systems.
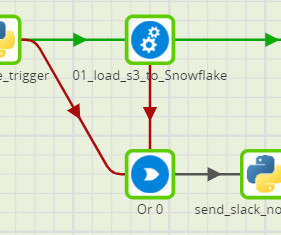
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
This article was published as a part of the Data Science Blogathon Snowflake is a clouddata platform that comes with a lot of unique features when compared to traditional on-premise RDBMS systems. The post 5 Features Of Snowflake That DataEngineers Must Know appeared first on Analytics Vidhya.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? using for loops in Python).
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Snowflake is a clouddata platform solution with unique features. The post Getting Started With Snowflake Data Platform appeared first on Analytics Vidhya.
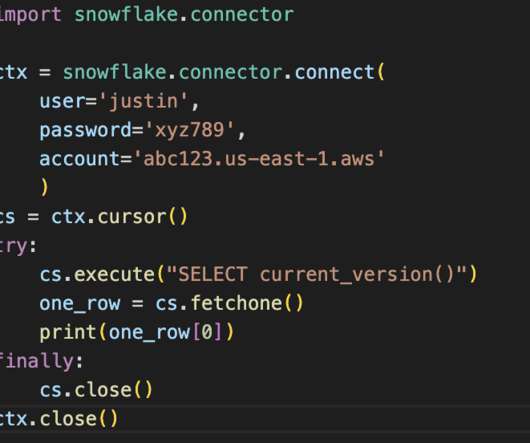
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
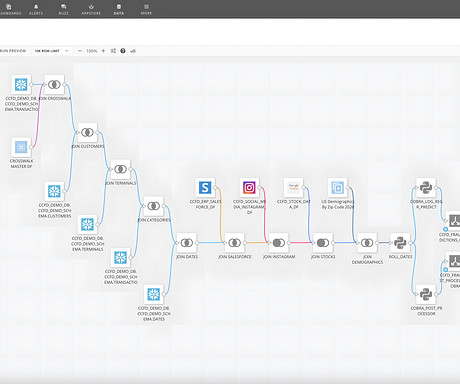
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Founded in 2016 by the creator of Apache Zeppelin, Zepl provides a self-service data science notebook solution for advanced data scientists to do exploratory, code-centric work in Python, R, and Scala. Data Exploration, Visualization, and First-Class Integration. And Even More to Come in 2021.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
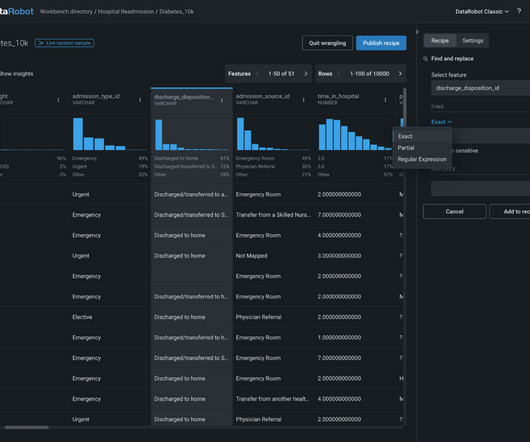
Proper data preparation leads to better model performance and more accurate predictions. SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. SageMaker Canvas recently added a Chat with data option. On the Create menu, choose Document.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices. Schedules cannot be edited or executed.
Deployment with the AWS CDK The Step Functions state machine and associated infrastructure (including Lambda functions, CodeBuild projects, and Systems Manager parameters) are deployed with the AWS CDK using Python. He is passionate about helping customers to build scalable and modern data analytics solutions to gain insights from the data.
The DataRobot team has been working hard on new integrations that make data scientists more agile and meet the needs of enterprise IT, starting with Snowflake. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
However, many analysts and other data professionals run into two common problems: They are not given direct access to their database They lack the skills in SQL to write the queries themselves The traditional solution to these problems is to rely on IT and dataengineering teams. What can be done?
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack. Data scientists.
Matillion Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into clouddata environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. Create a python function file that consists of all the ETL tasks – etl_functions.py.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Suppose your business requires more robust capabilities across your technology stack.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. You can use whatever works best for your technology.
Celonis versucht Machine Learning innerhalb der Plattform aus einer Hand anzubieten und hat auch eigene Python-Bibleotheken dafür entwickelt. Reduzierte Personalkosten , sind oft dann gegeben, wenn interne DataEngineers verfügbar sind, die die Datenmodelle intern entwickeln. Bisher dreht sich hier viel eher noch um z.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content