This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Connected Sheets, a business user could open a Sheet, enter data for a new property (square footage, number of bedrooms, location), and a formula can call a BQML model to return a price estimate. No Python or API wrangling needed - just a Sheets formula calling a model. It provides a Python API intentionally similar to pandas.
In this post, I’ll show you exactly how I did it with detailed explanations and Python code snippets, so you can replicate this approach for your next machine learning project or competition. The world’s leading publication for data science, data analytics, dataengineering, machine learning, and artificial intelligence professionals.
Entirely new paradigms rise quickly: cloudcomputing, dataengineering, machine learning engineering, mobile development, and large language models. To further complicate things, topics like cloudcomputing, software operations, and even AI don’t fit nicely within a university IT department.
Michelle Yi, Co-Founder of Generationship Michelle Yi is a technology leader who specializes in machine learning and cloudcomputing. He can teach you about Data Analysis, Java, Python, PostgreSQL, Microservices, Containers, Kubernetes, and some JavaScript.
Michelle Yi, Co-Founder of Generationship Michelle Yi is a technology leader who specializes in machine learning and cloudcomputing. He can teach you about Data Analysis, Java, Python, PostgreSQL, Microservices, Containers, Kubernetes, and some JavaScript.
Python: The demand for Python remains high due to its versatility and extensive use in web development, data science, automation, and AI. Python, the language that became the most used language in 2024, is the top choice for job seekers who want to pursue any career in AI. However, the competition is high.
In the ever-expanding world of data science, the landscape has changed dramatically over the past two decades. Once defined by statistical models and SQL queries, todays data practitioners must navigate a dynamic ecosystem that includes cloudcomputing, software engineering best practices, and the rise of generative AI.
Senior/Staff+ Engineer. Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. Python/Django deeply internalized; ideally Vue (or React) skills as well.
The post Using AWS S3 with Python boto3 appeared first on Analytics Vidhya. It allows users to store and retrieve files quickly and securely from anywhere. Users can combine S3 with other services to build numerous scalable […].
It aims to replace conventional backend servers for web and mobile applications by offering multiple services on the same platform like authentication, real-time database, Firestore (NoSQL database), cloud functions, […]. The post Introduction to Google Firebase Cloud Storage using Python appeared first on Analytics Vidhya.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
ArticleVideo Book This article was published as a part of the Data Science Blogathon In this article, we will learn to connect the Snowflake database. The post One-stop-shop for Connecting Snowflake to Python! appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems.
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. using for loops in Python). Infrastructure as Code (IaC) can be a game-changer in this scenario.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Introduction Many different datasets are available for data scientists, machine learning engineers, and dataengineers. Finding the best tools to evaluate each dataset […] The post Understanding Dask in Depth appeared first on Analytics Vidhya.
It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […]. Introduction Elasticsearch is a search platform with quick search capabilities.
This explains the current surge in demand for dataengineers, especially in data-driven companies. That said, if you are determined to be a dataengineer , getting to know about big data and careers in big data comes in handy. You should learn how to write Python scripts and create software.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Data science and dataengineering are incredibly resource intensive. By using cloudcomputing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Computer science, math, statistics, programming, and software development are all skills required in NLP projects. CloudComputing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Knowing some SQL is also essential.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
The Biggest Data Science Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
Data science is one of India’s rapidly growing and in-demand industries, with far-reaching applications in almost every domain. Not just the leading technology giants in India but medium and small-scale companies are also betting on data science to revolutionize how business operations are performed.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
Introduction What is an API? In simple terms, API is a messenger; let’s understand this with some examples. Let’s say you are hungry and you need to cook something at home. If you want to make noodles, you just take the ingredients out of the cupboard, fire up the stove, and make it yourself. This […].
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? The post Data Science Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A Data Warehouse is Built by combining data from multiple. The post A Brief Introduction to the Concept of Data Warehouse appeared first on Analytics Vidhya.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
Introduction Data has become an essential part of our daily lives in today’s digital age. From searching for a product on e-commerce platforms to placing an order and receiving it at home, we are constantly generating and consuming data.
This article was published as a part of the Data Science Blogathon. As we all have observed, the growth of data how helps the companies to get insights into data, and that insight is used for the growth of Business. Introduction An ultimate beginners guide on Apache Spark & RDDs!
What do machine learning engineers do: They analyze data and select appropriate algorithms Programming skills To excel in machine learning, one must have proficiency in programming languages such as Python, R, Java, and C++, as well as knowledge of statistics, probability theory, linear algebra, and calculus.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, I will be demonstrating how to deploy. The post Deploying PySpark Machine Learning models with Google Cloud Platform using Streamlit appeared first on Analytics Vidhya.
Key Skills Proficiency in programming languages like Python and R. Strong understanding of data preprocessing and algorithm development. Data Scientist Data Scientists analyze complex data sets to extract meaningful insights that inform business decisions. Proficiency in programming languages like Python and SQL.
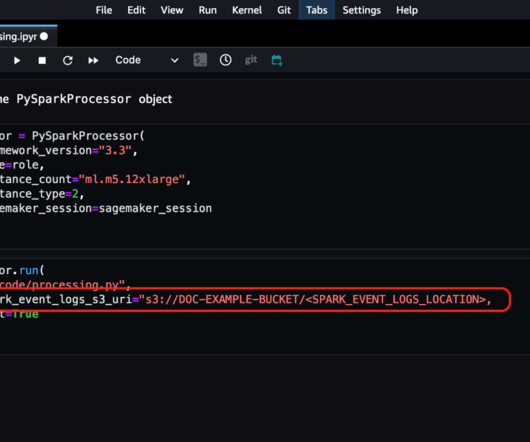
For the SageMaker Processing job, you can configure the Spark event log location directly from the SageMaker Python SDK. With the Spark UI hosted on SageMaker, machine learning (ML) and dataengineering teams can use scalable cloudcompute to access and analyze Spark logs from anywhere and speed up their project delivery.
The data would be further interpreted and evaluated to communicate the solutions to business problems. There are various other professionals involved in working with Data Scientists. This includes DataEngineers, Data Analysts, IT architects, software developers, etc.
Mustafa Hajij introduced TopoX, a comprehensive Python suite for topological deep learning. This session demonstrated how to leverage these tools using Python and PyTorch, offering attendees practical techniques to apply in their research and projects. Introduction to Containers for Data Science / DataEngineering with Michael A.
Introduction to Containers for Data Science/DataEngineering Michael A Fudge | Professor of Practice, MSIS Program Director | Syracuse University’s iSchool In this hands-on session, you’ll learn how to leverage the benefits of containers for DS and dataengineering workflows.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























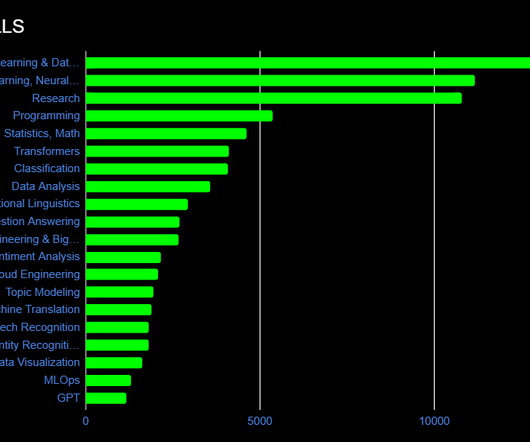
























Let's personalize your content