This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Resources: "Think Stats" by Allen Downey Khan Academys Statistics course Coding component: Use Pythons scipy.stats and pandas for hands-on practice. You can start with cleandata from sources like seaborns built-in datasets, then graduate to messier real-world data.
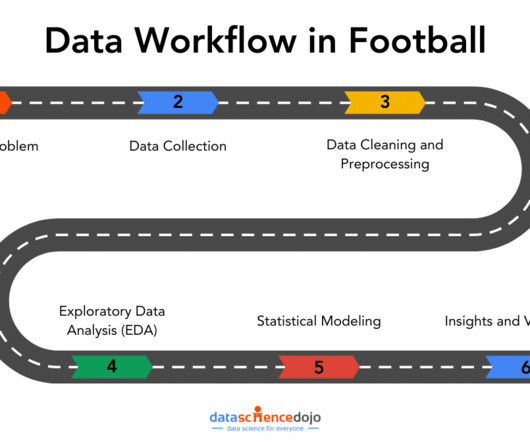
Whether youre passionate about football or data, this journey highlights how smart analytics can increase performance. Defining the Problem The starting point for any successful data workflow is problem definition. Data profiling helps identify issues such as missing values, duplicates, or outliers.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
With their technical expertise and proficiency in programming and engineering, they bridge the gap between data science and software engineering. Programming skills: Data scientists should be proficient in programming languages such as Python, R, or SQL to manipulate and analyze data, automate processes, and develop statistical models.
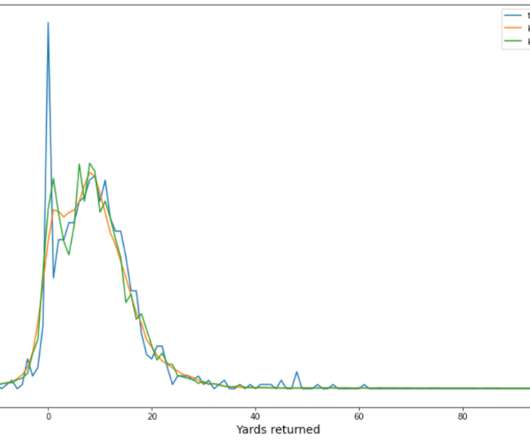
The downside of this approach is that we want small bins to have a high definition picture of the distribution, but small bins mean fewer data points per bin and our distribution, especially the tails, may be poorly estimated and irregular. We used the SBP distribution provided by GluonTS.
Moreover, this feature helps integrate data sets to gain a more comprehensive view or perform complex analyses. DataCleaningData manipulation provides tools to clean and preprocess data. Thus, Cleaningdata ensures data quality and enhances the accuracy of analyses.
You know that there is a vocabulary exam type of question in SAT that asks for the correct definition of a word that is selected from the passage that they provided. The AI generates questions asking for the definition of the vocabulary that made it to the end after the entire filtering process. So I tried to think of something else.
For more details on the definition of various forms of this score, please refer to part 1 of this blog. We also see how fine-tuning the model to healthcare-specific data is comparatively better, as demonstrated in part 1 of the blog series. client('bedrock-runtime') bedrock_agent_client = boto3.client("bedrock-agent-runtime",
Understanding Data Science Data Science is a multidisciplinary field that combines statistics, mathematics, computer science, and domain-specific knowledge to extract insights and wisdom from structured and unstructured data. Programming Languages (Python, R, SQL) Proficiency in programming languages is crucial.
Understanding Data Science At its core, Data Science is all about transforming raw data into actionable information. It includes data collection, datacleaning, data analysis, and interpretation. Programming and Data Manipulation Data Scientists often work with large datasets.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. Must Check Out: How to Use ChatGPT APIs in Python: A Comprehensive Guide.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Handling Missing Data: Imputing missing values or applying suitable techniques like mean substitution or predictive modelling.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
The following figure represents the life cycle of data science. It starts with gathering the business requirements and relevant data. Once the data is acquired, it is maintained by performing datacleaning, data warehousing, data staging, and data architecture. Why is datacleaning crucial?
Customers must acquire large amounts of data and prepare it. This typically involves a lot of manual work cleaningdata, removing duplicates, enriching and transforming it. Unlike in fine-tuning, which takes a fairly small amount of data, continued pre-training is performed on large data sets (e.g.,
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
If you’re hoping to deploy with success in the real world, this is definitely worth the read. Why Model Deployment Matters in Machine Learning? Model deployment is the essential (and final) step in the process of building a machine learning solution, and it finally takes your model from the lab into the real world.
The trafilatura library provides a command-line interface (CLI) and Python SDK for translating HTML documents in this fashion. The following code snippet demonstrates the librarys usage by extracting and preprocessing the HTML data from the Fine-tune Meta Llama 3.1 models using torchtune on Amazon SageMaker blog post.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content