This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datascientists play a crucial role in today’s data-driven world, where extracting meaningful insights from vast amounts of information is key to organizational success. As the demand for data expertise continues to grow, understanding the multifaceted role of a datascientist becomes increasingly relevant.
Machine learning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and datascientists have gained prominence.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Data Science is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A DataScientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
DataQuality and Privacy Concerns: AI models require high-qualitydata for training and accurate decision-making. Ensuring data privacy and security is vital, especially when handling sensitive user information.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for datascientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
Real-World Example: Healthcare systems manage a huge variety of data: structured patient demographics, semi-structured lab reports, and unstructured doctor’s notes, medical images (X-rays, MRIs), and even data from wearable health monitors. Ensuring dataquality and accuracy is a major challenge.
Knowing them and adopting the right way to overcome these will help you become a proficient datascientist. 10 Mistakes That a Data Analyst May Make Failing to Define the Problem Identifying the problem area is significant. However, many datascientist fail to focus on this aspect.
In today's business landscape, relying on accurate data is more important than ever. The phrase "garbage in, garbage out" perfectly captures the importance of dataquality in achieving successful data-driven solutions.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Missing data can lead to inaccurate results and biased analyses. Datascientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. What are the best data preprocessing tools of 2023?
It combines elements of statistics, mathematics, computer science, and domain expertise to extract meaningful patterns from large volumes of data. Role of DataScientists in Modern Industries DataScientists drive innovation and competitiveness across industries in today’s fast-paced digital world.
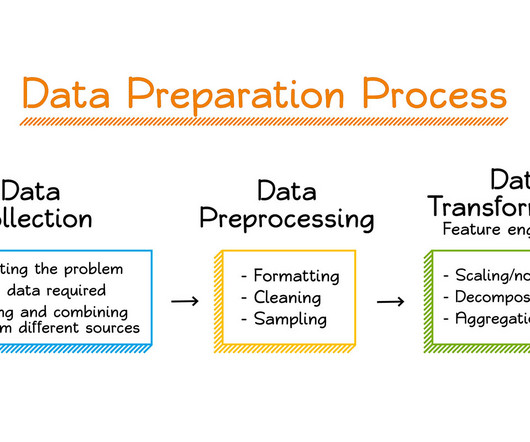
It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality. Introduction Data preprocessing is a critical step in the Machine Learning pipeline, transforming raw data into a clean and usable format.
Solution overview As mentioned earlier, the AWS services that you can use for analysis of mobility data are Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend, and Amazon SageMaker geospatial capabilities. Datascientists can accomplish this process by connecting through Amazon SageMaker notebooks.
This phase is crucial for enhancing dataquality and preparing it for analysis. Transformation involves various activities that help convert raw data into a format suitable for reporting and analytics. Normalisation: Standardising data formats and structures, ensuring consistency across various data sources.
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within datacleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
Sonal discussed the main challenges of NLP being ambiguity, context understanding, dataquality, bias and fairness, multilingual support, handling of sensitive data, and real world adaptability. Bias, Explainability and privacy are the major ethical issues of AI. With issues also come the challenges. What is the future of NLP?
It is a central hub for researchers, datascientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. Pandas are widely use for handling missing data and cleaningdata frames, while Scikit-learn provides tools for normalisation and encoding.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. CleaningData: Address any missing values or outliers that could skew results.
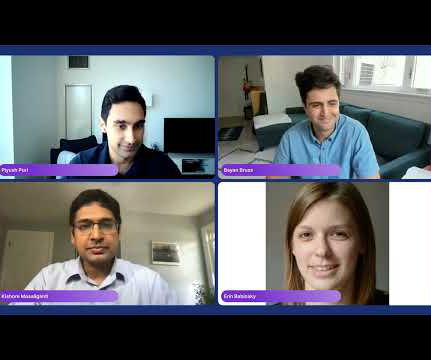
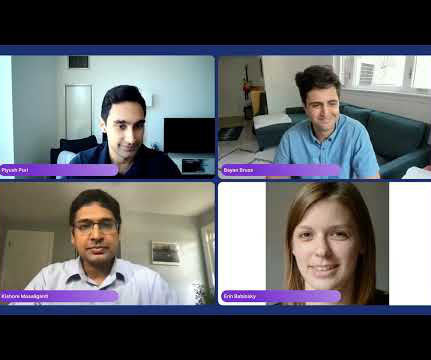
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. All right, so let’s set the stage first with some examples: a focus on dataquality leads to better ML-powered products.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. All right, so let’s set the stage first with some examples: a focus on dataquality leads to better ML-powered products.
Nowadays, we are surrounded by data: We produce a lot of personal data and work with a significant amount of data. When it comes to the business environment, data is crucial for effective decision-making, which makes it a highly valuable resource. Click to learn more about author Daniel Pullen.
So, let me present to you an Importing Data in Python Cheat Sheet which will make your life easier. For initiating any data science project, first, you need to analyze the data. You probably already know that there are a bunch of ways to do that, depending on what kind of files you are working with.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
While data preparation for machine learning may not be the most “glamorous” aspect of a datascientist’s job, it is the one that has the greatest impact on the quality of model performance and consequently the business impact of the machine learning product or service.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. This process ensures that the dataset is of high quality and suitable for machine learning. We’re committed to supporting and inspiring developers and engineers from all walks of life.
It’s about how to draw and analyze dataquality and machine learning quality, which is actually very related to this current trend of data-centric AI. You could have a missing value, you could have a wrong value, and you have a whole bunch of those data examples. CZ: Thank you! Learn more, live!
It’s about how to draw and analyze dataquality and machine learning quality, which is actually very related to this current trend of data-centric AI. You could have a missing value, you could have a wrong value, and you have a whole bunch of those data examples. CZ: Thank you! Learn more, live!
If you are an aspiring datascientist, or working professional looking to better understand this critical step in the ML Lifecycle, a Machine Learning Course could provide you the foundation and practical experience to avoid these problems. Most of the time projects fail during the deployment step, because of unexpected challenges.
Introduction: The Problem With AI Ideas As a DataScientist, I often find that every second person I talk to has a potential AI use case in mind. Common reasons include poor dataquality, unclear business value, and spiraling costs. Accessing relevant, high-qualitydata is tough. Can this be automated?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










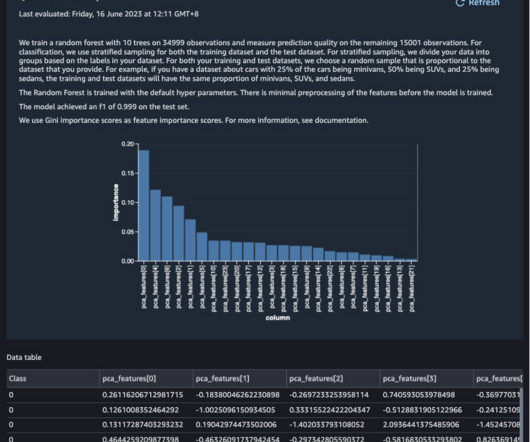






















Let's personalize your content