This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
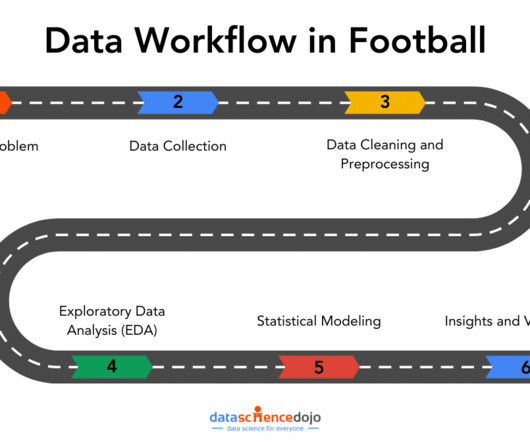
Typically, datasets can have errors, missing values, or inconsistencies, so ensuring your data is clean and well-structured is essential for accurate analysis. Dataprofiling helps identify issues such as missing values, duplicates, or outliers.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Validate Data Perform a final quality check to ensure the cleaneddata meets the required standards and that the results from data processing appear logical and consistent. Uniform Language Ensure consistency in language across datasets, especially when data is collected from multiple sources.
Reliability Reliable data can be trusted to be accurate and consistent over time. It should be free from bias, and the methods used to collect and process the data should be well-documented and transparent. Relevance Relevance measures whether the data is appropriate and valuable for the intended purpose.
Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while data scientists require cleandata for training machine learning models. Without high-quality data, even the most advanced models can't deliver value.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content