This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Importance of data preprocessing The role of data preprocessing cannot be overstated, as it significantly influences the quality of the dataanalysis process. High-qualitydata is paramount for extracting knowledge and gaining insights.
Roles and responsibilities of a data scientist Data scientists are tasked with several important responsibilities that contribute significantly to data strategy and decision-making within an organization. Analyzing data trends: Using analytic tools to identify significant patterns and insights for business improvement.
Summary: DataAnalysis and interpretation work together to extract insights from raw data. Analysis finds patterns, while interpretation explains their meaning in real life. Overcoming challenges like dataquality and bias improves accuracy, helping businesses and researchers make data-driven choices with confidence.
Summary: The Data Science and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Qualitydata is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. DataCleaningDatacleaning is crucial for data integrity.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
It involves data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and correlations that can drive decision-making. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
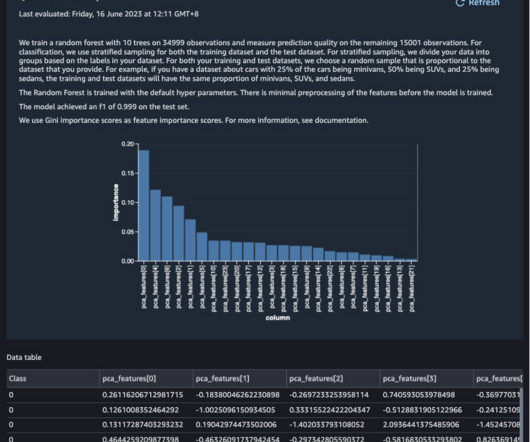
To quickly explore the loan data, choose Get data insights and select the loan_status target column and Classification problem type. The generated DataQuality and Insight report provides key statistics, visualizations, and feature importance analyses. Now you have a balanced target column.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Data preparation.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Data preparation.
Introduction Are you struggling to decide between data-driven practices and AI-driven strategies for your business? Besides, there is a balance between the precision of traditional dataanalysis and the innovative potential of explainable artificial intelligence. What are the Three Biggest Challenges of These Approaches?
Real-World Example: Healthcare systems manage a huge variety of data: structured patient demographics, semi-structured lab reports, and unstructured doctor’s notes, medical images (X-rays, MRIs), and even data from wearable health monitors. Ensuring dataquality and accuracy is a major challenge.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
Moreover, ignoring the problem statement may lead to wastage of time on irrelevant data. Overlooking DataQuality The quality of the data you are working on also plays a significant role. Dataquality is critical for successful dataanalysis.
Data manipulation in Data Science is the fundamental process in dataanalysis. The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
The ultimate objective is to enhance the performance and accuracy of the sentiment analysis model. Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data.
This phase is crucial for enhancing dataquality and preparing it for analysis. Transformation involves various activities that help convert raw data into a format suitable for reporting and analytics. Normalisation: Standardising data formats and structures, ensuring consistency across various data sources.
Summary: This comprehensive guide explores data standardization, covering its key concepts, benefits, challenges, best practices, real-world applications, and future trends. By understanding the importance of consistent data formats, organizations can improve dataquality, enable collaborative research, and make more informed decisions.
Summary: Data scrubbing is identifying and removing inconsistencies, errors, and irregularities from a dataset. It ensures your data is accurate, consistent, and reliable – the cornerstone for effective dataanalysis and decision-making. Overview Did you know that dirty data costs businesses in the US an estimated $3.1
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Data Lakes allow for flexible analysis.
These tasks include dataanalysis, supplier selection, contract management, and risk assessment. DataQuality The effectiveness of AI depends on high-qualitydata. Poor data can lead to inaccurate insights and decisions. Conduct a data audit to identify gaps or inconsistencies in your datasets.
Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy. Introduction Are you a Python enthusiast looking to import data into your code with ease?
Duplicates can significantly affect DataAnalysis and reporting in several ways: Inflated Metrics: Duplicates can lead to inflated totals or averages, which misrepresent the actual data. Skewed Insights: Analysis based on duplicated data can result in incorrect conclusions and impact decision-making.
With the help of data pre-processing in Machine Learning, businesses are able to improve operational efficiency. Following are the reasons that can state that Data pre-processing is important in machine learning: DataQuality: Data pre-processing helps in improving the quality of data by handling the missing values, noisy data and outliers.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. CleaningData: Address any missing values or outliers that could skew results.
DataCleaning: Raw data often contains errors, inconsistencies, and missing values. Datacleaning identifies and addresses these issues to ensure dataquality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
Now that you know why it is important to manage unstructured data correctly and what problems it can cause, let's examine a typical project workflow for managing unstructured data. Focus on Metadata Management First Implementing robust metadata management is crucial for making unstructured data more manageable and accessible.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. This process ensures that the dataset is of high quality and suitable for machine learning.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. This is to say that cleandata can better teach our models.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. This is to say that cleandata can better teach our models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content