This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The key is having a reliable, reusable system that handles the mundane tasks so you can focus on extracting insights from cleandata. Happy datacleaning! She likes working at the intersection of math, programming, data science, and content creation. 🔗 You can find the complete script on GitHub.
Mitigation strategies against GIGO Proactively managing data quality is essential in counteracting GIGO. Several strategies can enhance the reliability and accuracy of data inputs. Cross-validation of data sources Combining data from multiple sources promotes robustness.
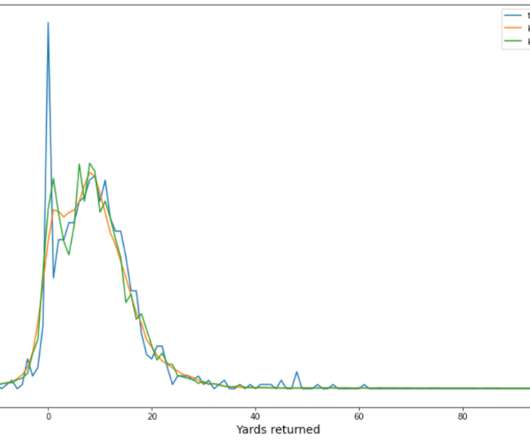
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. To avoid leakage during cross-validation, we grouped all plays from the same game into the same fold. For more information on how to use GluonTS SBP, see the following demo notebook.
DataCleaning: Eliminate theNoise Why it matters : Noisy, incomplete, or inconsistent data can sink even the best-trained model. What youll do: Cleaning involves handling missing values, correcting errors, standardizing formats, and filtering outliers. Its not just about performanceits abouttrust. Unlock theFuture.
Step 3: Data Preprocessing and Exploration Before modeling, it’s essential to preprocess and explore the data thoroughly.This step ensures that you have a clean and well-understood dataset before moving on to modeling. CleaningData: Address any missing values or outliers that could skew results.
The following figure represents the life cycle of data science. It starts with gathering the business requirements and relevant data. Once the data is acquired, it is maintained by performing datacleaning, data warehousing, data staging, and data architecture. What is Cross-Validation?
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. He has collaborated with the Amazon Machine Learning Solutions Lab in providing cleandata for them to work with as well as providing domain knowledge about the data itself.
Datacleaning identifies and addresses these issues to ensure data quality and integrity. Data Analysis: This step involves applying statistical and Machine Learning techniques to analyse the cleaneddata and uncover patterns, trends, and relationships.
Here, we’ll explore why Data Science is indispensable in today’s world. Understanding Data Science At its core, Data Science is all about transforming raw data into actionable information. It includes data collection, datacleaning, data analysis, and interpretation.
This process often involves cleaningdata, handling missing values, and scaling features. Feature extraction automatically derives meaningful features from raw data using algorithms and mathematical techniques. Cross-validation ensures these evaluations generalise across different subsets of the data.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. Use a representative and diverse validation dataset to ensure that the model is not overfitting to the training data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content