This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. Prompt 2: Were there any major world events in 2016 affecting the sale of Vegetables?
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Lambda enables serverless, event-driven data processing tasks, allowing for real-time transformations and calculations as data arrives. Step Functions complements this by orchestrating complex workflows, coordinating multiple Lambda functions, and managing error handling for sophisticated data processing pipelines.
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. 5 Key Comparisons in Different Apache Kafka Architectures.
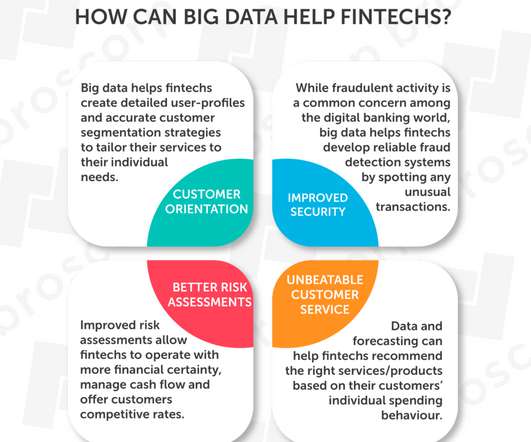
Historical financial big data helps businesses scrutinize evolving customer behaviors, allowing them to come up with invaluable products and services that streamline banking processes. However, to take full advantage of big data’s powerful capabilities, choosing BI and ETL solutions cannot be over-emphasized.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
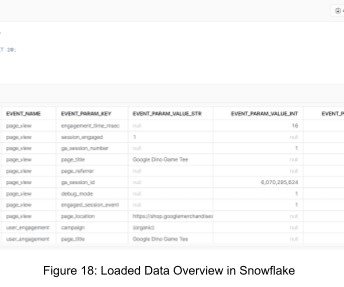
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. By the end of this tutorial, you’ll have a seamless pipeline that fetches and syncs your GA4 raw eventsdata to Snowflake efficiently.
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
Data analytics is a task that resides under the data science umbrella and is done to query, interpret and visualize datasets. Data scientists will often perform data analysis tasks to understand a dataset or evaluate outcomes. Diagnostic analytics: Diagnostic analytics helps pinpoint the reason an event occurred.
If you’re not familiar with DGIQ, it’s the world’s most comprehensive event dedicated to, you guessed it, data governance and information quality. This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders. His major takeaway?
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Interested in attending an ODSC event?
Traditional maintenance activities rely on a sizable workforce distributed across key locations along the BHS dispatched by operators in the event of an operational fault. From now on, we will launch a retraining every 3 months and, as soon as possible, will use up to 1 year of data to account for the environmental condition seasonality.
This is the practice of creating, updating and consistently enforcing the processes, rules and standards that prevent errors, data loss, data corruption, mishandling of sensitive or regulated data, and data breaches. Effective data security protocols and tools contribute to strong data integrity.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
Unfortunately, even the data science industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with businessintelligence rather than AI, leading to a dismissive attitude toward its sophistication.
Data Warehouse: Its significance and relevance in the data world. Exploring Differences: Database vs Data Warehouse. Role in Data Warehousing and BusinessIntelligence Dimensional modelling plays a crucial role in data warehousing and businessintelligence by structuring data to enhance performance and usability.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling businessintelligence and analytics is growing exponentially, giving birth to cloud solutions. Data warehousing is a vital constituent of any businessintelligence operation.
In today’s digital world, data is king. Organizations that can capture, store, format, and analyze data and apply the businessintelligence gained through that analysis to their products or services can enjoy significant competitive advantages. But, the amount of data companies must manage is growing at a staggering rate.
A complete view of the fan, rather than pieces of information spread across various departments, means less guesswork and more data insights. Step 2: Analyze the Data Once you have centralized your data, use a businessintelligence tool like Sigma Computing , Power BI , Tableau , or another to craft analytics dashboards.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. Supports the ability to interact with the actual data and perform analysis on it. This provides the facility a time or event for a job to run and offers useful post-run information. Scheduling.
Data Quality Dimensions Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following: Accuracy indicates how correctly data reflects the real-world entities or events it represents.
Other users Some other users you may encounter include: Data engineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party businessintelligence tools and the data platform, is not separate.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content