This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
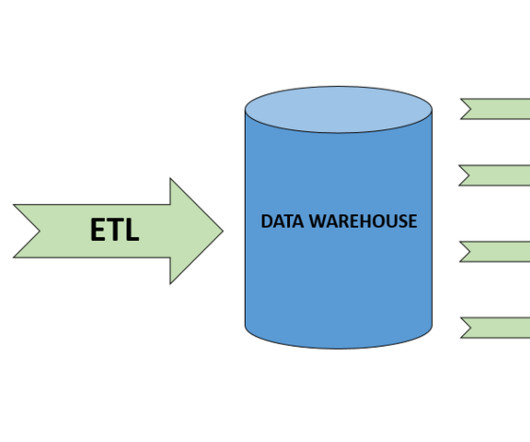
When it comes to data, there are two main types: datalakes and data warehouses. Which one is right for your business? What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications.
It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features. It provides a scalable and fault-tolerant ecosystem for big data processing. Spark offers a rich set of libraries for data processing, machinelearning, graph processing, and stream processing.
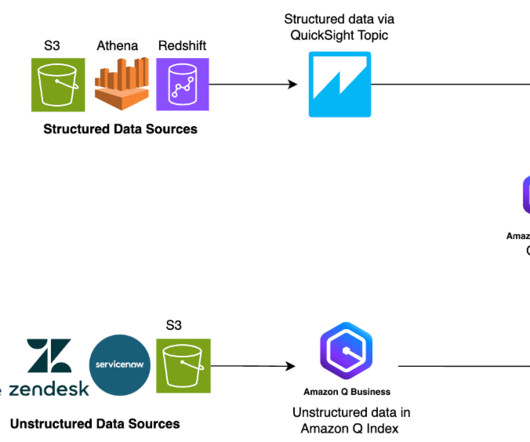
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, datalakes, and real-time reports). Different types of data typically require different tools to access them.
Enterprises often rely on data warehouses and datalakes to handle big data for various purposes, from businessintelligence to data science. A new approach, called a data lakehouse, aims to …
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
By setting up automated policy enforcement and checks, you can achieve cost optimization across your machinelearning (ML) environment. Tags can be added at an Amazon DataZone domain and used for organizing data assets, users, and projects. Implement a tagging strategy A tag is a label you assign to an AWS resource.
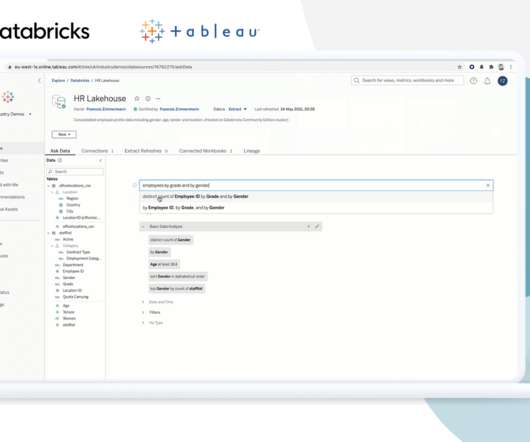
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Summary: Understanding BusinessIntelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery. What is BusinessIntelligence Architecture?
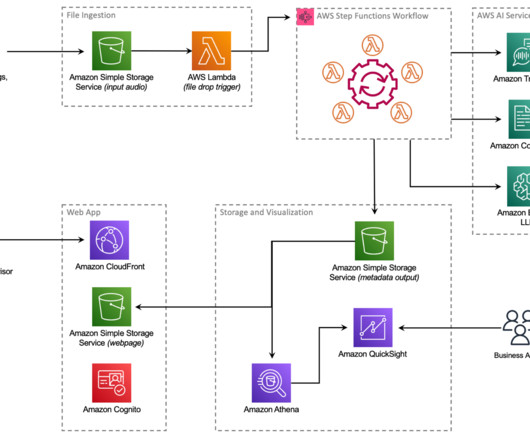
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time MachineLearning with Spark and SBERT Learn more about real-time machinelearning by using this approach that uses Apache Spark and SBERT. Register for free!
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Data models help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for businessintelligence. Ensure that data is clean, consistent, and up-to-date.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
An interactive analytics application gives users the ability to run complex queries across complex data landscapes in real-time: thus, the basis of its appeal. Interactive analytics applications present vast volumes of unstructured data at scale to provide instant insights. Amazon Redshift is a fast and widely used data warehouse.
However, to gain such smart recommendations, we sacrifice our data privacy. Such applications leverage datalakes full of our historical user data to provide these smart recommendations. Data consumers on-chain can query and purchase the data that they need from these IoT outputs. Ocean Protocol x Fetch.ai
Although generative AI is fueling transformative innovations, enterprises may still experience sharply divided data silos when it comes to enterprise knowledge, in particular between unstructured content (such as PDFs, Word documents, and HTML pages), and structured data (real-time data and reports stored in databases or datalakes).
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for businessintelligence and reporting purposes. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. You can even connect directly to 20+ data sources to work with data within minutes.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearning models and develop artificial intelligence (AI) applications.
Unfortunately, the current landscape of our consuming systems, especially businessintelligence tools, just wont work withAPIs. He has a passion for helping organizations understand the true potential of their data by working as a leader, architect, and builder.
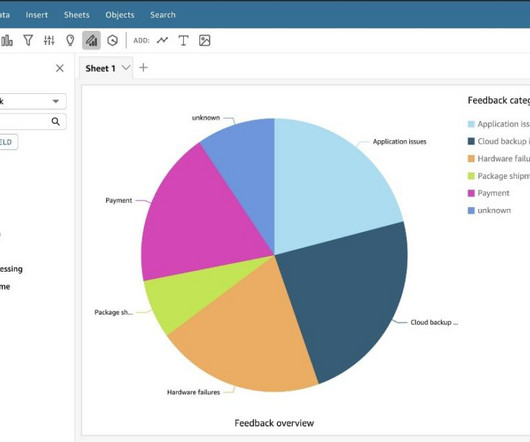
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device. The Step Functions workflow starts.
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
Apache Spark Apache Spark is a unified analytics engine for Big Data processing, with built-in modules for streaming, SQL, MachineLearning , and graph processing. Key Features : Speed : Spark processes data in-memory, making it up to 100 times faster than Hadoop MapReduce in certain applications.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other businessintelligence (BI) tools. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like MachineLearning. Aggregation : Combining multiple data points into a single summary (e.g.,
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud data ingestion, storage, machinelearning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. This organization manages fleets of globally distributed edge gateways.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
It involves using statistical and computational techniques to identify patterns and trends in the data that are not readily apparent. Data mining is often used in conjunction with other data analytics techniques, such as machinelearning and predictive analytics, to build models that can be used to make predictions and inform decision-making.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
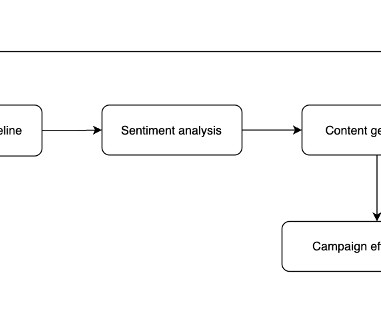
This pattern creates a comprehensive solution that transforms raw social media data into actionable businessintelligence (BI) through advanced AI capabilities. 3B Instruct Amazon Bedrock, the system provides tailored marketing content that adds business value. By integrating LLMs such as Anthropics Claude 3.5
Think of it as building plumbing for data to flow smoothly throughout the organization. EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machinelearning to responsible AI.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). It can be used with both on-premise and multi-cloud environments.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling businessintelligence and analytics is growing exponentially, giving birth to cloud solutions. Data warehousing is a vital constituent of any businessintelligence operation.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machinelearning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
Here’s an overview of the key characteristics: AI-powered analytics : Integration of AI and machinelearning capabilities into OLAP engines will enable real-time insights, predictive analytics and anomaly detection, providing businesses with actionable insights to drive informed decisions.
A modern data catalog is more than just a collection of your enterprise’s every data asset. It’s also a repository of metadata — or data about data — on information sources from across the enterprise, including data sets, businessintelligence reports, and visualizations.
Summary: Power BI is a businessintelligence tool that transforms raw data into actionable insights. Introduction Managing business and its key verticals can be challenging. However, with the surge of data tools like Power BI, you can not only manage the data, but at the same time draw actionable insights from it.
They’re built on machinelearning algorithms that create outputs based on an organization’s data or other third-party big data sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content