This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. What is a dataengineer?
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale.
Deeply integrated with the lakehouse, Lakebase simplifies operational data workflows. It eliminates fragile ETL pipelines and complex infrastructure, enabling teams to move faster and deliver intelligent applications on a unified data platform In this blog, we propose a new architecture for OLTP databases called a lakebase.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Salary Trends – Salaries for machine learning engineers typically range from $100,000 to $150,000 per year, with highly experienced professionals earning salaries exceeding $200,000. BusinessIntelligence Analyst Businessintelligence analysts are responsible for gathering and analyzing data to drive strategic decision-making.
It combines the cost-effectiveness and flexibility of data lakes with the performance and reliability of data warehouses. This hybrid approach facilitates advanced analytics, machine learning, and businessintelligence, streamlining data processing and insights generation.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of businessintelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models. This process is known as data integration , one of the key components to improving the usability of data for AI and other use cases, such as businessintelligence (BI) and analytics.
Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. What makes the difference is a smart ETL design capturing the nature of process mining data. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from businessintelligence , process mining and data science.
. Request a live demo or start a proof of concept with Amazon RDS for Db2 Db2 Warehouse SaaS on AWS The cloud-native Db2 Warehouse fulfills your price and performance objectives for mission-critical operational analytics, businessintelligence (BI) and mixed workloads.
Just like this in Data Science we have Data Analysis , BusinessIntelligence , Databases , Machine Learning , Deep Learning , Computer Vision , NLP Models , Data Architecture , Cloud & many things, and the combination of these technologies is called Data Science.
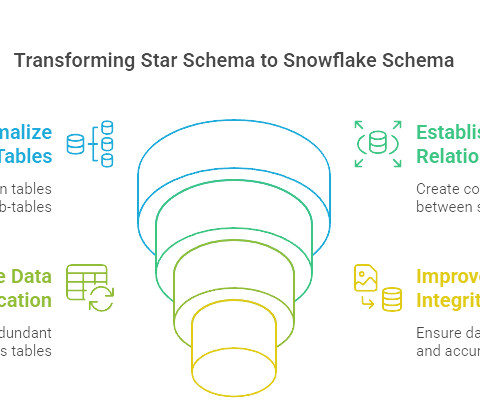
Information is stored only once, reducing storage needs and improving data consistency. This makes it ideal for analytical queries and businessintelligence reporting where speed is critical. Query Performance Star Schema Delivers faster query performance since fewer joins are needed.
A data warehouse acts as a single source of truth for an organization’s data, providing a unified view of its operations and enabling data-driven decision-making. A data warehouse enables advanced analytics, reporting, and businessintelligence. Data integrations and pipelines can also impact latency.
A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. Businessintelligence (BI) platforms. The rise of cloud computing and cloud data warehousing has catalyzed the growth of the modern data stack.
Using Amazon QuickSight for anomaly detection Amazon QuickSight is a fast, cloud-powered, businessintelligence service that delivers insights to everyone in the organization. With ML-powered anomaly detection, customers can find outliers in their data without the need for manual analysis, custom development, or ML domain expertise.
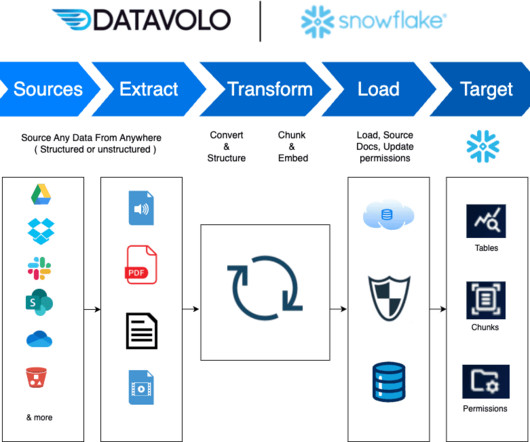
Over the years, businesses have increasingly turned to Snowflake AI Data Cloud for various use cases beyond just data analytics and businessintelligence. Datavolo is more than just an ETL toolit provides functionality for Reverse ETL as well, enabling organizations to push data from Snowflake into other systems.
Inconsistent or unstructured data can lead to faulty insights, so transformation helps standardise data, ensuring it aligns with the requirements of Analytics, Machine Learning , or BusinessIntelligence tools. This makes drawing actionable insights, spotting patterns, and making data-driven decisions easier.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. The Open Connector Framework SDK enables engineers to custom-build data source connectors , which are indexed by Alation. Open Data Quality Initiative. “At
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for businessintelligence and data science use cases.
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for businessintelligence and reporting purposes. What is a Data Lake?
With the “Data Productivity Cloud” launch, Matillion has achieved a balance of simplifying source control, collaboration, and dataops by elevating Git integration to a “first-class citizen” within the framework. In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g.,
Sample Dataflow Graph Declarative APIs make ETL simpler and more maintainable Through years of working with real-world Spark users, we’ve seen common challenges emerge when building production pipelines: Too much time spent wiring together pipelines with “glue code” to handle incremental ingestion or deciding when to materialize datasets.
With an estimated market share of 30.03% , Microsoft Fabric is a preferred choice for businesses seeking efficient and scalable data solutions. Definition and Core Components Microsoft Fabric is a unified solution integrating various data services into a single ecosystem. What is Power BI?
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. ” Vitaly Tsivin, EVP BusinessIntelligence at AMC Networks.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
Data warehouses have their own data modeling approaches that are typically more rigid than those for a data lake. Raw Central Repository Data lakes can serve as a central repository for integrating data from various sources, such as databases, data warehouses, APIs, and external data feeds.
The implementation of a data vault architecture requires the integration of multiple technologies to effectively support the design principles and meet the organization’s requirements. Data Vault Automation Working at scale can be challenging, especially when managing the data model.
However, building data-driven applications can be challenging. It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves dataengineers, data scientists, and business analysts using different systems and tools.
Data environments in data-driven organizations are changing to meet the growing demands for analytics , including businessintelligence (BI) dashboarding, one-time querying, data science , machine learning (ML), and generative AI.
Data Analysis and Transition to Machine Learning: Skills: Python, SQL, Excel, Tableau and Power BI are relevant skills for entry-level data analysis roles. Next Steps: Transition into dataengineering (PySpark, ETL) or machine learning (TensorFlow, PyTorch). MySQL, PostgreSQL) and non-relational (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















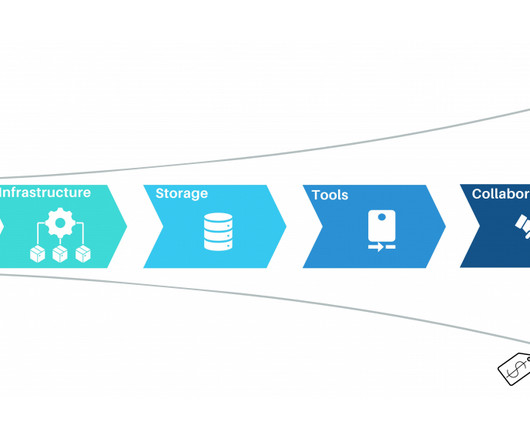























Let's personalize your content