This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a Data Engineer, extracting data from. The post Implementing ETL Process Using Python to Learn Data Engineering appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to ETLETL as the name suggests, Extract Transform and. The post Pandas Vs PETL for ETL appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
A Brief Introduction to Papers With Code; Machine Learning Books You Need To Read In 2022; Building a Scalable ETL with SQL + Python; 7 Steps to Mastering SQL for Data Science; Top Data Science Projects to Build Your Skills.
Python works best for: Exploratory data analysis and prototyping Machine learning model development Complex ETL with business logic Statistical analysis and research Data visualization and reporting Go: Built for Scale and Speed Go takes a different approach to data processing, focusing on performance and reliability from the start.
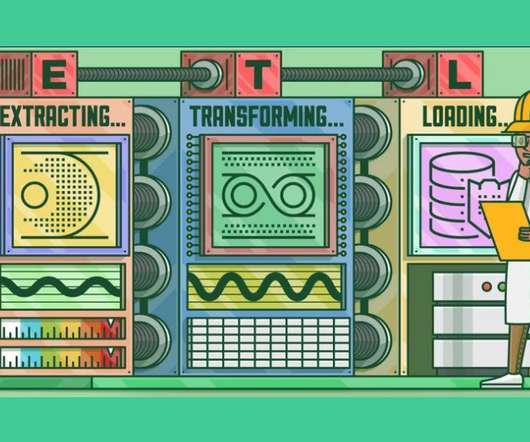
In this article, we will look at some data engineering basics for developing a so-called ETL pipeline. In the case of training an LLM, we probably want to scrap text from various sources, such as Wikipedia, open books, datasets on hugging-face, etc. The whole thing is very exciting, but where do I get the data from?
Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. Specifically, your job is to create a JSON representation of an ETL pipeline which will solve the user request provided to you.
or book a demo: https://cal.com/shreyashn/chonkie-demo. reply snyy 5 hours ago | parent | next [–] As mentioned in the other reply, we have a cloud/on-prem offering that comes with a managed ETL pipeline built on top of our OSS offering. If you're interested, reach out at shreyash@chonkie.ai
I worked extensively with ETL processes, PostgreSQL, and later, enterprise-scale data systems. Many companies struggle with data silos, so we focus on centralizing data, optimizing ETL processes, and enabling real-time analytics. Q: Do you have any book recommendations? Q: Tell me more about Data Surge?
Teams needing subsecond decisions often push enriched events to Kafka or Kinesis via Snowbridge ; those consolidating on a warehouse can stream straight into Snowflake through the Snowplow Streaming Loader no duplicate ETL required. Trainingserving skew Source both phases from the same feature store. Ready to move from theory to throughput?
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. What is a Datamart?
Read this e-book on building strong governance foundations Why automated data lineage is crucial for success Data lineage , the process of tracking the flow of data over time from origin to destination within a data pipeline, is essential to understand the full lifecycle of data and ensure regulatory compliance.
It’s useful for coordinating tasks, distributed processing, ETL (extract, transform, and load), and business process automation. Outside of work, he spends his time building things and watching comic book movies with his family. It handles the underlying complexity so you can focus on application logic.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. In Alation, lineage provides added advantages of being able to add data flow objects, such as ETL transformations, perform impact analysis, and manually edit lineage. Book a demo today. The post Alation 2022.2:
Data warehouse disciplines and architectures are well established and often discussed in the press, books, and conferences. Data warehouse (DW) testers with data integration QA skills are in demand. They have become a standard necessity for most modern organizations. Each business often uses one or more data […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? appeared first on Analytics Vidhya.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
Data Processing: Snowflake can process large datasets and perform data transformations, making it suitable for ETL (Extract, Transform, Load) processes. If you’d like a more personalized look into the potential of Snowflake for your business, definitely book one of our free Snowflake migration assessment sessions.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines.
In her book, Data lineage from a business perspective , Dr. Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Critical and quick bridges The demand for lineage extends far beyond dedicated systems such as the ETL example.
You don’t have to write ETL jobs.” That lowers the barrier to entry because you don’t have to be an ETL developer. Register (and book a meeting with our team). Anyone building anything net-new publishes to Snowflake in a database driven by the use case and uses our commoditized web-based GUI ingestion framework.
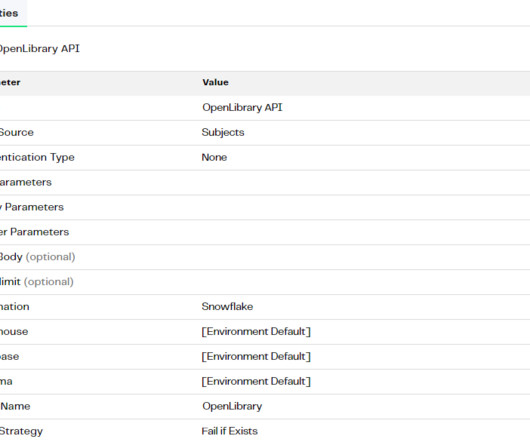
For this project, we will utilize a simple OpenLibrary API to find many books based on a subject and a time window. Now, we’ll make a GET request to the following endpoint, which is set up to look for analytics books released between 2014 and 2024. Each API has its own set of requirements.
Tips When Considering Streamsets Data Collector: As a Snowflake partner, Streamsets includes very intricate documentation on using Data Collector with Snowflake, including this book you can read here. Data Collector can use Snowflake’s native Snowpipe in its pipelines.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. We had books to make a model run in Spark or on a large box. How is DAGWorks different from other popular solutions?
If transitional modeling is like building with Legos, then activity schema modeling is like creating a flip book animation of your customer’s journey. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data. What is Activity Schema Modeling?
Seamless AWS Integration Works effortlessly with AWS S3 (data storage), AWS Lambda (serverless computing), and AWS Glue (ETL). And also here the best book to start your Machine Learning journey in. SageMaker Pipelines provides automated workflow capabilities for MLOps pipelines. Your team has limited ML expertise.
Next Steps: Transition into data engineering (PySpark, ETL) or machine learning (TensorFlow, PyTorch). Data Pipelines and Orchestration : Familiarity with tools like Airflow (workflow orchestration), Kafka (real-time data processing), and ETL pipelines is critical for creating efficient data workflows. 📣 Want to advertise in AIM?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content