This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Datawarehouse generalizes and mingles data in multidimensional space. The post How to Build a DataWarehouse Using PostgreSQL in Python? appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
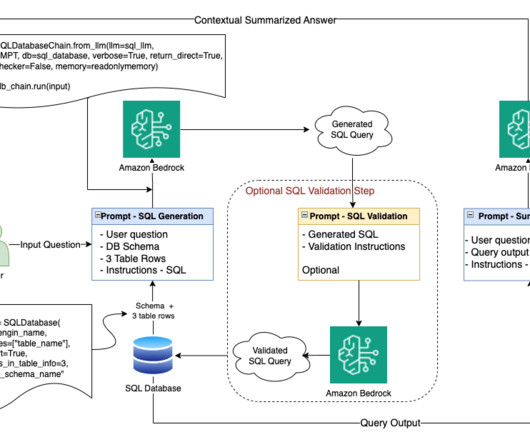
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Aspiring and experienced Data Engineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best Data Engineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is Data Engineering?
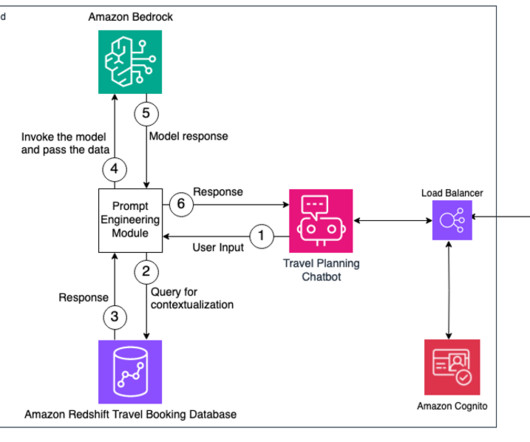
We use prompt engineering techniques to develop and optimize the prompts with the data that is stored in a Redshift database to efficiently use the foundation models. The solution uses their bookingdata to look up the cities they are going to, along with the travel dates, and comes up with a precise, personalized list of things to do.
The Datamarts capability opens endless possibilities for organizations to achieve their data analytics goals on the Power BI platform. This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling.
They are also designed to handle concurrent access by multiple users and applications, while ensuring data integrity and transactional consistency. Examples of OLTP databases include Oracle Database, Microsoft SQL Server, and MySQL. An OLAP database may also be organized as a datawarehouse.
Answer : Along with standard RDS features, Amazon RDS for Db2 supports key Db2 features, such as row and column organized tables for mixed and analytic workloads, the Adaptive Workload Optimizer to for better resource management, and rules-based access controls for advanced data protection. Scalability 5. . Amazon RDS
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape. Book a demo today.
Regarding retrieval, DBMS utilises query languages like SQL to retrieve information swiftly and accurately based on user requests. Moreover, DBMS systems manage data through functionalities such as indexing, which enhances retrieval speed by logically organising data. Best Data Engineering and SQLBooks for Beginners.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data. My time is up.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data. My time is up.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data. My time is up.
It’s also the mechanism that brings data consumers and data producers closer together. Our legacy architecture, like that at most organizations, is a massive on-prem enterprise datawarehouse,” Lavorini says. “As As we modernize our core banking platforms, the data goes with that modernization journey.”
Understanding SQL Index: The Key to Faster Query Execution Exploring SQL Index: Basics, Types, Benefits, and Query Optimization Image From Pexels Index is a very crucial topic in SQL. Indexes are the silent partners in SQL, working behind the scenes to make queries sing. What is the Index in SQL and need for it?
Some modern CDPs are starting to incorporate these concepts, allowing for more flexible and evolving customer data models. It also requires a shift in how we query our customer data. Instead of simple SQL queries, we often need to use more complex temporal query languages or rely on derived views for simpler querying.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content