This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets. This approach not only enhances the efficiency of datapreparation but also improves the accuracy and relevance of AI models.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Aspiring and experienced Data Engineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best Data Engineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is Data Engineering?
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
Datapreparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained. Finally, it offers best practices for fine-tuning, emphasizing dataquality, parameter optimization, and leveraging transfer learning techniques.
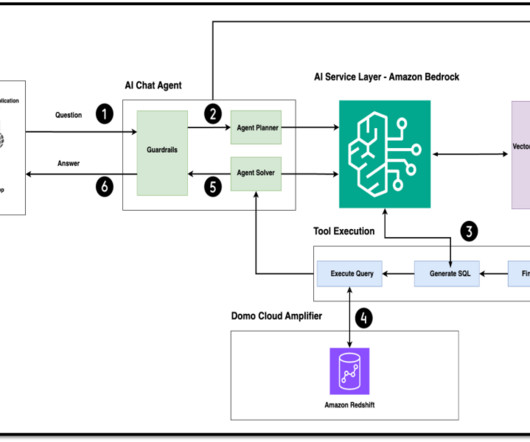
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Representation models encode meaningful features from raw data for use in classification, clustering, or information retrieval tasks. Book a demo today.
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Representation models encode meaningful features from raw data for use in classification, clustering, or information retrieval tasks. Book a demo today.
To read more about LLMOps and MLOps, checkout the O’Reilly book “Implementing MLOps in the Enterprise” , authored by Iguazio ’s CTO and co-founder Yaron Haviv and by Noah Gift. This includes versioning, ingestion and ensuring dataquality. What is LLMOps?
Source: Author Introduction Just like having a massive pile of books won't make you a genius unless you read and understand them, a mountain of data won't make a powerful AI if it's not properly labeled. Source: Author SuperAnnotate helps annotate data with a wide range of tools like bounding boxes, polygons, and speech tagging.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content