This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
This can be useful for data scientists who need to streamline their data science pipeline or automate repetitive tasks. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
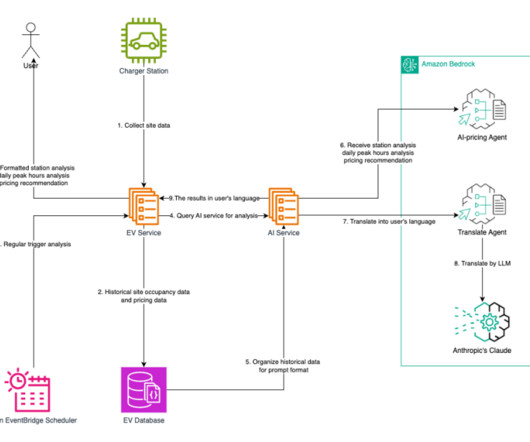
To meet the feature requirements, the system operation process includes the following steps: Charging data is processed through the EV service before entering the database. The charging history data and pricing data are stored in the EV database.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
Aspiring and experienced Data Engineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best Data Engineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is Data Engineering?
The solution extracts valuable insights from diverse data sources, including OEM transactions, vehicle specifications, social media reviews, and OEM QRT reports. By employing a multi-modal approach, the solution connects relevant data elements across various databases.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Its sales analysts face a daily challenge: they need to make data-driven decisions but are overwhelmed by the volume of available information. They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model. The value of data lineage applies across all industries, but there are three key focuses when you consider it for banking use cases: 1.
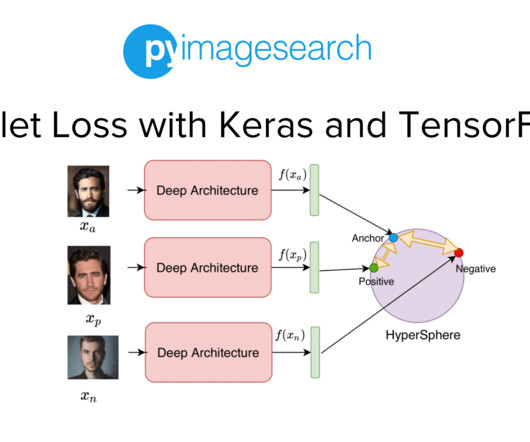
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
To further enrich the dataset, Fastweb generated synthetic Italian data using LLMs. High-quality Italian web articles, books, and other texts served as the basis for training the LLMs to generate authentic-sounding synthetic content that captured the nuances of the language.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. Download the code!
You have a specific book in mind, but you have no idea where to find it. You enter the title of the book into the computer and the library’s digital inventory system tells you the exact section and aisle where the book is located. After all, Alex may not be aware of all the data available to her.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
Anyone building anything net-new publishes to Snowflake in a database driven by the use case and uses our commoditized web-based GUI ingestion framework. DataPipeline Capabilities This team’s scope is massive because the datapipelines are huge and there are many different capabilities embedded in them.
A cloud data warehouse is designed to combine a concept that every organization knows, namely a data warehouse, and optimizes the components of it, for the cloud. If you’d like a more personalized look into the potential of Snowflake for your business, definitely book one of our free Snowflake migration assessment sessions.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Booking – This demonstrates an example of routing the caller to a live agent queue. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. Choose Create data source.
Market participants who are receiving either live or historical data feeds need to ingest this data and perform one or more steps, such as parse the message out of a binary protocol, rebuild the limit order book (LOB), or combine multiple feeds into a single normalized format.
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of datapipelines.
What is Semi-structured Data? Semi-structured data, also called partially structured data, is a form that does not adhere to the conventional tabular structure found in relational databases or other data tables. Semi-structured data can come from many sources, including applications, sensors, and mobile devices.
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. config.py ) The datapipeline (i.e., Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL! model.py ) Additionally, the robust.py
With new tools and frameworks emerging weekly, its natural to focus on tangible things we can controlwhich vector database to use, which LLM provider to choose, which agent framework to adopt. The real challenge is ensuring your synthetic data actually triggers the scenarios you want to test. This isnt surprising.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content