This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
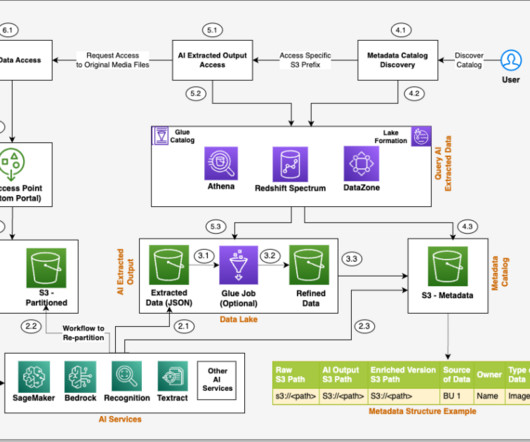
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is ML engineering a stressful job?
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book contains a full chapter dedicated to generative AI.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Data quality is ownership of the consuming applications or data producers. Governance The two key areas of governance are model and data: Model governance Monitor model for performance, robustness, and fairness. Model versions should be managed centrally in a model registry.
For data science practitioners, productization is key, just like any other AI or ML technology. However, it's important to contextualize generative AI within the broader landscape of AI and ML technologies. By doing so, you can ensure quality and production-ready models. Here’s to a successful 2024!
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. Model monitoring The performance of MLmodels is monitored for degradation over time.
Source: Author Introduction Machine learning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
For data science practitioners, productization is key, just like any other AI or ML technology. However, it's important to contextualize generative AI within the broader landscape of AI and ML technologies. By doing so, you can ensure quality and production-ready models. Here’s to a successful 2024!
From onboarding new customers to analyzing pictures or videos of damages for evaluation, machine learning (ML) and AI offer exciting possibilities for optimization and cost-saving across the insurance industry. Claims data is often noisy, unstructured, and multi-modal. Book a demo today.
To read more about LLMOps and MLOps, checkout the O’Reilly book “Implementing MLOps in the Enterprise” , authored by Iguazio ’s CTO and co-founder Yaron Haviv and by Noah Gift. LLMOps (Large Language Model Operations), is a specialized domain within the broader field of machine learning operations (MLOps). What is LLMOps?
From onboarding new customers to analyzing pictures or videos of damages for evaluation, machine learning (ML) and AI offer exciting possibilities for optimization and cost-saving across the insurance industry. Claims data is often noisy, unstructured, and multi-modal. Book a demo today.
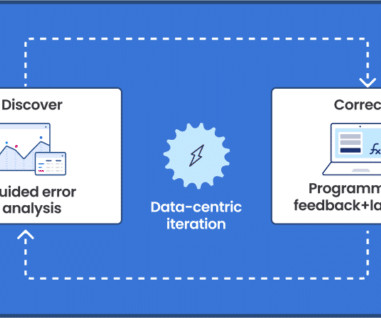
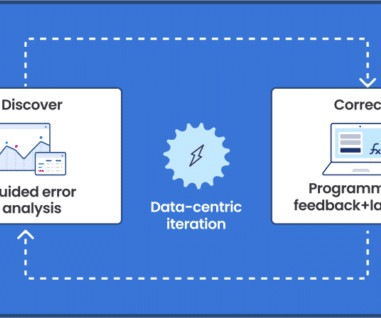
Today, I will be introducing you to LandingLens, our main product, and taking you through the journey we went through in developing that product and the data-centric approaches we’ve incorporated into the platform. The third objective is to help our customers get the most from their existing ML platforms.
Today, I will be introducing you to LandingLens, our main product, and taking you through the journey we went through in developing that product and the data-centric approaches we’ve incorporated into the platform. The third objective is to help our customers get the most from their existing ML platforms.
From onboarding new customers to analyzing pictures or videos of damages for evaluation, machine learning (ML) and AI offer exciting possibilities for optimization and cost-saving across the insurance industry. Claims data is often noisy, unstructured, and multi-modal. Book a demo today. See what Snorkel option is right for you.
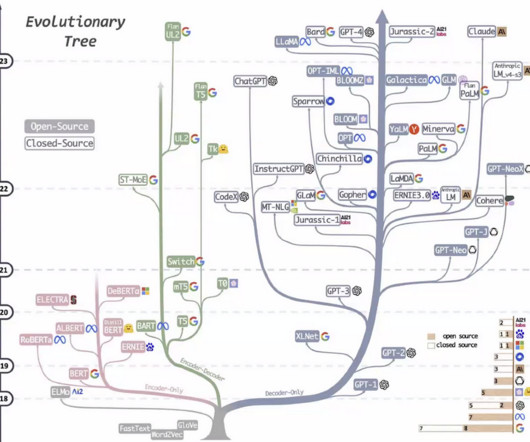
Unsurprisingly, Machine Learning (ML) has seen remarkable progress, revolutionizing industries and how we interact with technology. The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. Their mission?
It has helped to write a book. The world is full of uncreative boilerplate content that humans have to write: catalog entries, financial reports, back covers for books (I’ve written more than a few), and so on. At this point, it’s not clear how language models and their outputs fit into copyright law. What Is the Future?
Since intentions determine the subsequent domain identification flow, the intention stratum is a necessary first step in initiating contextual and domain datamodel processes. Mining data for creating knowledge graphs b. The technical framework for AliMe’s intention and matching stratification 2. AAAI Press, 2014: 1586–1592.
where each book represents a record, each chapter represents a field, and each shelf represents a table. These databases are the most common type used today and store data in a structured format using tables, rows, and columns. In this guide, we’ll cover the eight most popular types of databases. and let’s dive in!
The framework I’ve found most helpful is Contextual Integrity which was introduced by Helen Nissenbaum in the book Privacy in Context. With enough data, models can be created to “read between the lines” in both helpful and dangerous ways. Privacy is hard to understand. Video games already cater to multiple people’s experiences.
Think of it as a meticulously organized lab notebook, but one that can handle the complexity of modern ML workflows. It provides interactive charts and visualizations to help you gain insights into your model’s behavior. Visualization Tools : Visualizing your experiments’ progress is a breeze with Comet.
How implement modelsML fundamentals training and evaluation improve accuracy use library APIs Python and DevOps What when to use ML decide what models and components to train understand what application will use outputs for find best trade-offs select resources and libraries The “how” is everything that helps you execute the plan.
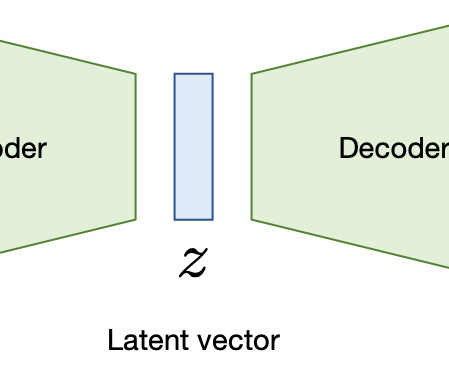
Vector Embeddings for Developers: The Basics | Pinecone Used geometry concept to explain what is vector, and how raw data is transformed to embedding using embedding model. A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. How do I develop my body of work?
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content