This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Introduction As the demand for data professionals continues to rise, understanding data warehousing concepts becomes increasingly essential for candidates preparing for interviews in 2025. Key Takeaways Understand the fundamental concepts of data warehousing for interviews. Can You Explain the ETL Process?
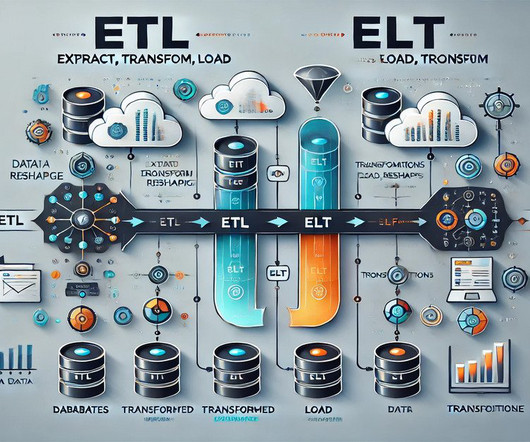
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
In data management, ETL processes help transform raw data into meaningful insights. As organizations scale, manual ETL processes become inefficient and error-prone, making ETL automation not just a convenience but a necessity.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
This blog post explores effective strategies for gathering requirements in your data project. Whether you are a data analyst , project manager, or data engineer, these approaches will help you clarify needs, engage stakeholders, and ensure requirements gathering techniques to create a roadmap for success.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
M aintaining the security and governance of data within a data warehouse is of utmost importance. Data ownership extends beyond mere possession—it involves accountability for dataquality, accuracy, and appropriate use. This includes defining data formats, naming conventions, and validation rules.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Business insights are only as good as the accuracy of the data on which they are built. According to Gartner, dataquality is important to organizations in part because poor dataquality costs organizations at least $12.9 million a year on average.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. You can review the recommendations and augment rules from over 25 included dataquality rules.
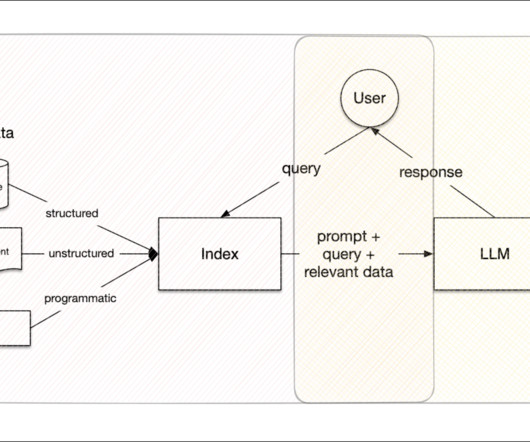
Read this blog on LlamaIndex to learn more in detail Features of LlamaIndex: LlamaIndex is an innovative tool designed to enhance the utilization of large language models (LLMs) by seamlessly connecting your data with the powerful computational capabilities of these models.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is Data Profiling in ETL?
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data. The post Big Data – Lambda or Kappa Architecture?
In my first business intelligence endeavors, there were data normalization issues; in my Data Governance period, DataQuality and proactive Metadata Management were the critical points. The post The Declarative Approach in a Data Playground appeared first on DATAVERSITY. It is something so simple and so powerful.
Introduction In today’s data-driven world, organisations strive to leverage their data for informed decision-making and strategic planning. However, many face significant barriers in the form of data silos. Key Takeaways Data silos limit access to critical information across departments.
At the same time, implementing a data governance framework poses some challenges, such as dataquality issues, data silos security and privacy concerns. Dataquality issues Positive business decisions and outcomes rely on trustworthy, high-qualitydata. ” Michael L.,
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
But, this data is often stored in disparate systems and formats. Here comes the role of Data Mining. Read this blog to know more about Data Integration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Thereby, improving dataquality and consistency.
Those who want to design universal data pipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each data pipeline platform embodies a unique philosophy, architectural design, and set of operations.
Data engineers can scan data connections into IBM Cloud Pak for Data to automatically retrieve a complete technical lineage and a summarized view including information on dataquality and business metadata for additional context.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
But raw data alone isn’t enough to gain valuable insights. This is where data warehouses come in – powerful tools designed to transform raw data into actionable intelligence. This blog delves into the world of data warehouses, exploring their functionality, key features, and the latest innovations.
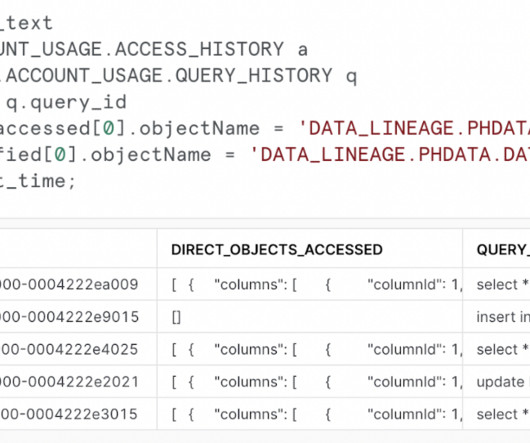
With its built-in data lineage capabilities, Snowflake allows organizations to directly capture, visualize, and analyze data lineage within its cloud-native environment. Data Integrity and Trust – Data lineage helps identify potential dataquality issues, troubleshoot data discrepancies, and ensure data integrity.
Data engineering is all about collecting, organising, and moving data so businesses can make better decisions. Handling massive amounts of data would be a nightmare without the right tools. In this blog, well explore the best data engineering tools that make data work easier, faster, and more reliable.
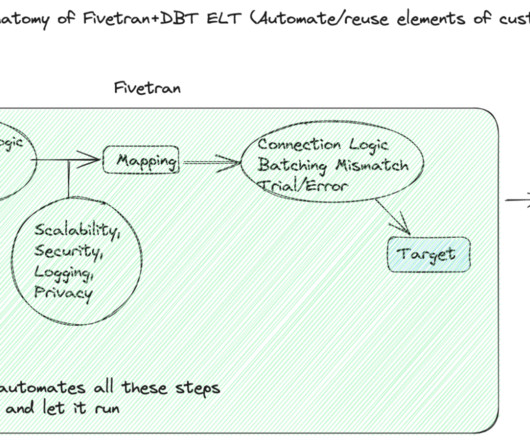
In our previous blog , we discussed how Fivetran and dbt scale for any data volume and workload, both small and large. Now, you might be wondering what these tools can do for your data team and the efficiency of your organization as a whole. Can these tools help reduce the time our data engineers spend fixing things?
That’s where data enrichment comes into the picture. In this blog post, we’ll explain what data enrichment is, why you need it, how it works, and how B2B companies can use enriched data to drive results. What is data enrichment? Better dataquality. Customer dataquality decays quickly.
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
To power AI and analytics workloads across your transactional and purpose-built databases, you must ensure they can seamlessly integrate with an open data lakehouse architecture without duplication or additional extract, transform, load (ETL) processes. Effective dataquality management is crucial to mitigating these risks.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It supports both batch and real-time processing.
This is a blog post from AWS to optimize cloud services costs. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Run the notebooks The sample code for this solution is available on GitHub.
Summary: This blog delves into hierarchies in dimensional modelling, highlighting their significance in data organisation and analysis. Real-world examples illustrate their application, while tools and technologies facilitate effective hierarchical data management in various industries.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Summary: This blog discusses best practices for designing effective fact tables in dimensional models. Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance.
Business Intelligence Analysts are the skilled artisans who transform this raw data into valuable insights, empowering organizations to make strategic decisions and stay ahead of the curve. Key Takeaways BI Analysts convert data into actionable insights for strategic business decisions. Identifying and resolving dataquality issues.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content