This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields. These blogs stand out as they make deep, complex topics easy to understand for a broader audience.
Data is the lifeblood of modern decision-making, and AI systems rely heavily on it. However, the quality and ethical implications of this data are paramount. The Importance of Ethical DataPreparation Ethical datapreparation is fundamental to the success of AI systems. One of the most significant is bias.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
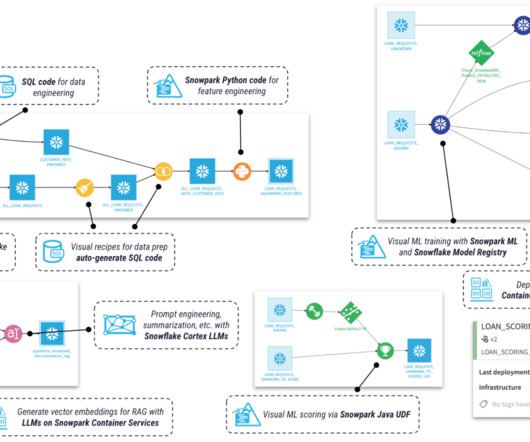
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications. One of the standout features of Dataiku is its focus on collaboration.
The workflow adapts automatically to any CSV structure, allowing you to quickly assess multiple datasets and prioritize your datapreparation efforts. Next Steps 1. Email Integration Add a Send Email node to automatically deliver reports to stakeholders by connecting it after the HTML node.
Datapreparation tools : Libraries such as Pandas, Scikit-learn pipelines, and Spark MLlib simplify data cleaning and transformation tasks. AutoML frameworks : Tools like Google AutoML and H2O.ai include automated feature engineering as part of their machine learning pipelines.
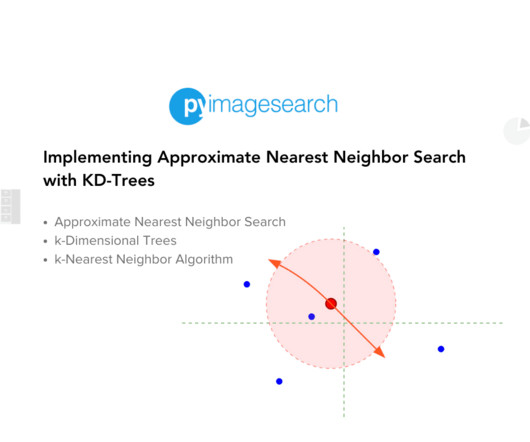
KD-Trees are a type of binary search tree that partitions data points into k-dimensional space, allowing for efficient querying of nearest neighbors. We will start by setting up libraries and datapreparation. One of the most effective methods to perform ANN search is to use KD-Trees (K-Dimensional Trees).
By creating microsegments, businesses can be alerted to surprises, such as sudden deviations or emerging trends, empowering them to respond proactively and make data-driven decisions. Choose Segment ColumnData Explanation: Segmenting column dataprepares the system to generate SQL queries for distinctvalues.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
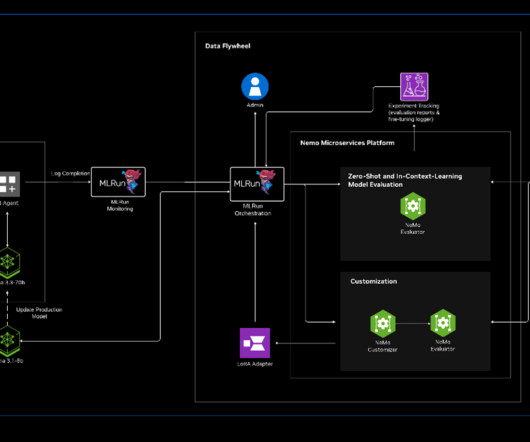
Read the blog for more details, or go straight to the blueprint to try it out for yourself. It automates datapreparation, model tuning, customization, validation and optimization of LLMs, ML models and live AI applications over elastic resources. What is MLRun?
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Have an S3 bucket to store your dataprepared for batch inference. Have an AWS Identity and Access Management (IAM) role for batch inference with a trust policy and Amazon S3 access (read access to the folder containing input data and write access to the folder storing output data).
Datapreparation For this example, you will use the South German Credit dataset open source dataset. After you have completed the datapreparation step, it’s time to train the classification model. An experiment collects multiple runs with the same objective.
For this walkthrough, we use a straightforward generative AI lifecycle involving datapreparation, fine-tuning, and a deployment of Meta’s Llama-3-8B LLM. Datapreparation In this phase, prepare the training and test data for the LLM. We use the SageMaker Core SDK to execute all the steps.
In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job.
Several activities are performed in this phase, such as creating the model, datapreparation, model training, evaluation, and model registration. Model lineage tracking captures and retains information about the stages of an ML workflow, from datapreparation and training to model registration and deployment.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
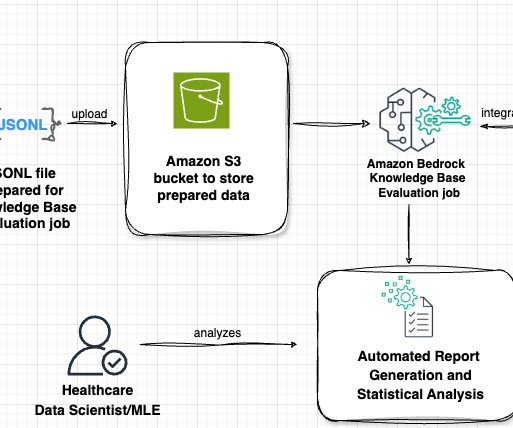
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
Organizations need a unified, streamlined approach that simplifies the entire process from datapreparation to model deployment. To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities.
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
Start a distillation job with S3 JSONL data using an API To use an API to start a distillation job using training data stored in an S3 bucket, follow these steps: First, create and configure an Amazon Bedrock client: import boto3 from datetime import datetime bedrock_client = boto3.client(service_name="bedrock")
Recommended Learning Resources The Illustrated Transformer (Blog & Visual Guide): A must-read visual explanation of transformer models. It covers the entire process, from datapreparation to model training and evaluation, enabling viewers to adapt LLMs for specific tasks or domains.
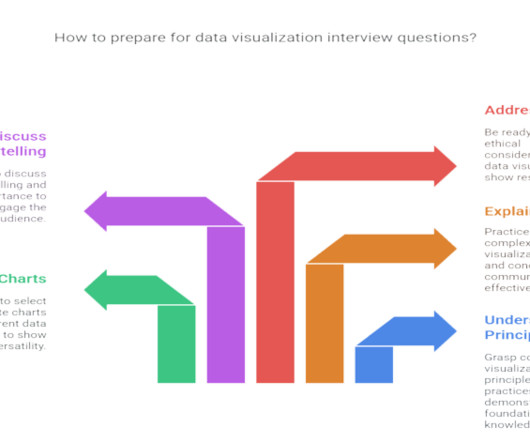
This blog post breaks down top data visualization interview questions into two categories: Beginner and Advanced. Whether you’re just starting or looking to step into a more senior role, these examples and expert answers will help you prepare and impress. The approach depends on the context and the amount of missing data.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
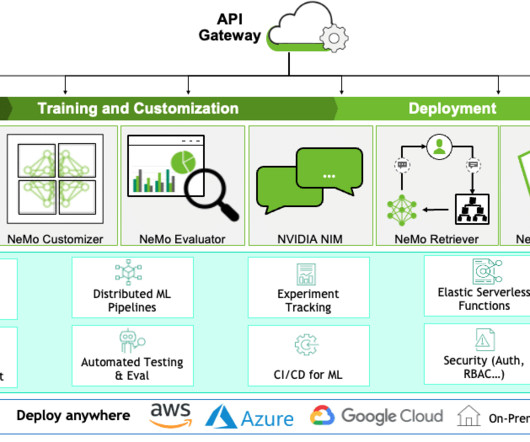
In this blog post, we spotlight a leading player in the gen AI infrastructure ecosystem, NVIDIA , commonly known for their GPUs, software and research that have helped drive gen AI implementation and research. We introduce their new solution model deployment - NVIDIA NIM.
In our previous blog posts, we explored various techniques such as fine-tuning large language models (LLMs), prompt engineering, and Retrieval Augmented Generation (RAG) using Amazon Bedrock to generate impressions from the findings section in radiology reports using generative AI. Part 1 focused on model fine-tuning.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. In this section, we cover how to discover these models in SageMaker Studio.
To address potential fairness concerns, it can be helpful to evaluate disparities and imbalances in training data or outcomes. Amazon SageMaker Clarify helps identify potential biases during datapreparation without requiring code.
MLRun automates key processes such as datapreparation, model tuning, customization, validation and optimization for ML models, LLMs and live AI applications across scalable, elastic infrastructure.
In this piece, we explore practical ways to define data standards, ethically scrape and clean your datasets, and cut out the noise whether youre pretraining from scratch or fine-tuning a base model. If youre working on LLMs, this is one of those foundations thats easy to overlook but hard to ignore. 👉 Read the post here!
This approach was use case-specific and required datapreparation and manual work. We would like to acknowledge Thomaz Silva and Saeed Elnaj for their contributions to this blog. Before LLMs for text-to-SQL, user queries had to be preprocessed to match specific templates, which were then used to rephrase the queries.
This approach enables centralized access and sharing while minimizing extract, transform and load (ETL) processes and data duplication. Integrated vectorized embedding capabilities streamline datapreparation for various applications such as retrieval augmented generation (RAG) and other machine learning and generative AI use cases.
Sigma offers powerful mapping capabilities that allow users to visualize geographic data effectively. Whether you’re analyzing regional trends, plotting locations, or visualizing complex geographical data, Sigma Maps can help you gain valuable insights. In this blog, we will cover how to use maps in Sigma Computing.
The architecture incorporates best practices in MLOps, making sure that the different stages of the ML lifecyclefrom datapreparation to production deploymentare optimized for performance and reliability. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Solution walkthrough (Scenario 1) The first step focuses on preparing the data for each data source for unified access.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
Teaching Language Models Complex New Verbs Fine-tuning large language models (LLMs) has become the default method for tailoring AI systems to specific tasks, yet it often comes with significant drawbacks: high computational costs, brittleness from overfitting, catastrophic forgetting, and substantial datapreparation hurdles.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. A prolific educator, Julien shares his knowledge through code demos, blogs, and YouTube, making complex AI accessible.
It seems like that's not the main focus of your org, but I was pleased to see a reference to RCV in your blog: [0] [0]: https://goodparty.org/blog/article/final-five-voting-explain. eu/knowledge-hub/blog and https://www.ml6.eu/customers/cases
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science. Huong Nguyen is a Sr.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content