This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
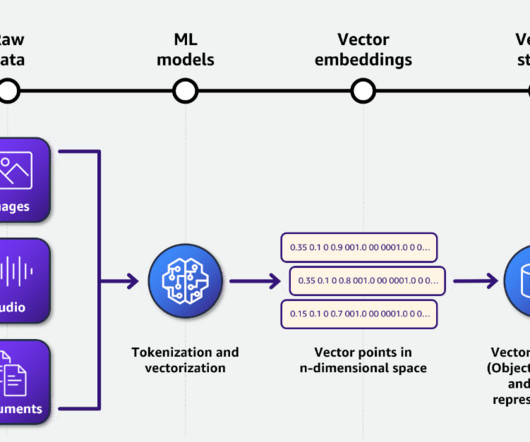
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Ideal for data scientists and engineers working with databases and complex datamodels. It also includes free machine learning books, courses, blogs, newsletters, and links to local meetups and communities.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
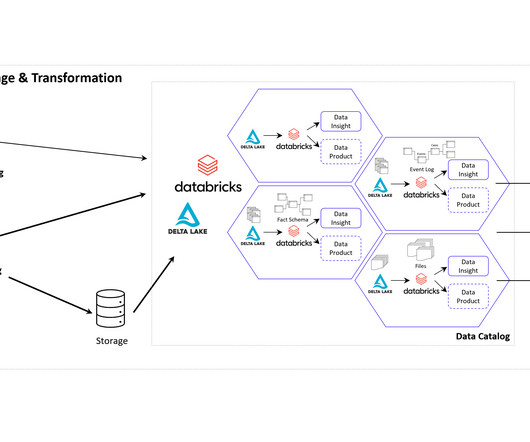
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. With the concept of Data Mesh you will be able to access all your organizational internal and external data sources once and provides the data as several datamodels for all your analytical applications.
Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, data scientists, and system administrators. This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Data science myths are one of the main obstacles preventing newcomers from joining the field. In this blog, we bust some of the biggest myths shrouding the field. The US Bureau of Labor Statistics predicts that data science jobs will grow up to 36% by 2031. Data scientists only work on predictive modeling Another myth!
Dataengineering refers to the design of systems that are capable of collecting, analyzing, and storing data at a large scale. In manufacturing, dataengineering aids in optimizing operations and enhancing productivity while ensuring curated data that is both compliant and high in integrity.
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. In this blog, we’re featuring Eugenia Pais, a Sr. DataEngineer at phData. DataEngineer? As a Senior DataEngineer, I wear many hats. DataEngineer appeared first on phData.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
In turn, the same will happen in dataengineering. Autonomous agents will re-architect the data lifecycle, from datamodelling and infrastructure-as-code to platform migrations, CI/CD, governance, and ETL pipelines. With these foundations in place, unlocking value in unstructured data becomes easier.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven DataModeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
With the integration of SageMaker and Amazon DataZone, it enables collaboration between ML builders and dataengineers for building ML use cases. ML builders can request access to data published by dataengineers. Also, you can update the model’s deploy status.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Apache HBase was employed to offer real-time key-based access to data. Data is stored in HDFS and is accessed via Hive, which provides a tabular interface to the data and integrates with Spark SQL.
As Indian companies across industries increasingly embrace data-driven decision-making, artificial intelligence (AI), and automation, the demand for skilled data scientists continues to surge. Validation techniques ensure models perform well on unseen data.
DataEngineering A dataengineers start to simplification Introduction A lot of time folks start directly jumping into KPIs ( Key Performace Indicators) without understanding the need for those KPIs. I have met with clients who have dumped all the data they had and never figured out what they really wanted to achieve.
Just as a chef’s masterpiece depends on the quality of the ingredients, your AI outcomes will depend on the data you prepare. Investing in your data can only lead to positive results. The post Looking Ahead: The Future of Data Preparation for Generative AI appeared first on Data Science Blog.
Dataengineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need dataengineers. The journey to becoming a successful dataengineer […].
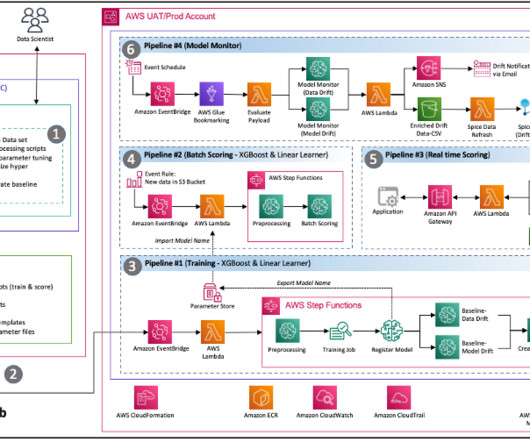
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Data scientists will typically perform data analytics when collecting, cleaning and evaluating data. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model.
Collectively, these modules address governance across various dimensions, such as infrastructure, data, model, and cost. Reference architecture modules The reference architecture comprises eight modules, each designed to solve a specific set of problems.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, datamodeling, and dataengineering. About the Author Rajendra Choudhary is a Sr. Business Analyst at Amazon. He is passionate about supporting customers by leveraging generative AIbased solutions.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It also lets you choose the right engine for the right workload at the right cost, potentially reducing your data warehouse costs by optimizing workloads.
If you’re interested in learning more, we highly recommend checking out our comprehensive blog that covers this in much more detail. How to Connect Power BI to Snowflake Choose Import or Directquery Mode Carefully Power BI offers two main connection types when connecting to data sources, Import and DirectQuery.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized dataengineers understood, resulting in an under-realized positive impact on the business.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows dataengineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
It uses advanced tools to look at raw data, gather a data set, process it, and develop insights to create meaning. Areas making up the data science field include mining, statistics, data analytics, datamodeling, machine learning modeling and programming. appeared first on IBM Blog.
By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including: Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members.
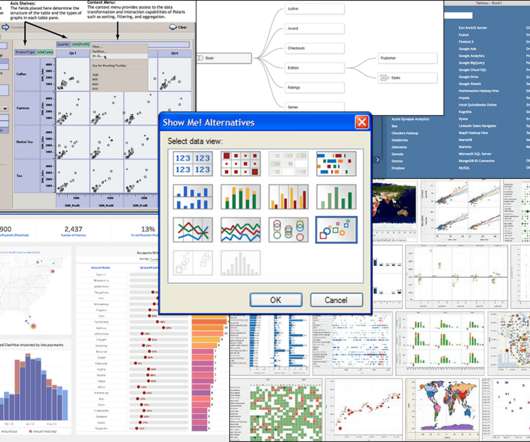
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. April 2018), which focused on users who do understand joins and curating federated data sources.
By changing the cost structure of collecting data, it increased the volume of data stored in every organization. Additionally, Hadoop removed the requirement to model or structure data when writing to a physical store. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
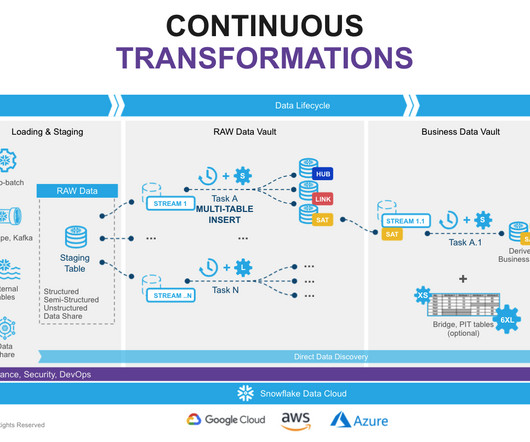
In this blog, our focus will be on exploring the data lifecycle along with several Design Patterns, delving into their benefits and constraints. Data architects can leverage these patterns as starting points or reference models when designing and implementing data vault architectures.
Fivetran is a fully-automated, zero-maintenance data pipeline tool that automates the ETL process from data sources to your cloud warehouse. It eliminates the need for time-consuming dataengineering tasks to maintain the pipeline and allows businesses to spend more time analyzing their data instead of maintaining it.
But do they empower many user types to quickly find trusted data for a business decision or datamodel? Many data catalogs suffer from a lack of adoption because they are too technical. These include data analysts, stewards, business users , and dataengineers. Subscribe to Alation's Blog.
This is the last of the 4-part blog series. In the previous blog , we discussed how Alation provides a platform for data scientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active data governance. Subscribe to Alation's Blog.
We document these custom models in Alation Data Catalog and publish common queries that other teams can use for operational use cases or reporting needs. Contact title mappings, which are buiilt in some of datamodels, are documented within our data catalog. Jason: How do you use these models?
Blog - Everest Group Requirements gathering: ChatGPT can significantly simplify the requirements gathering phase by building quick prototypes of complex applications. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Monitor the data, models, and applications to guarantee their availability and performance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content