
Announcing General Availability of Liquid Clustering
databricks
MAY 22, 2024
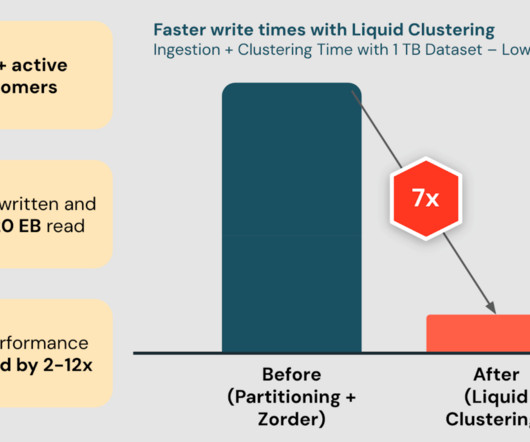
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
databricks
MAY 22, 2024
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.

databricks
APRIL 7, 2023
We are excited to announce that cluster policies are now generally available. Why Databricks cluster policies? Databricks cluster policies enable administrators to: limit.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
DECEMBER 5, 2024
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.

databricks
MAY 10, 2023
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.

databricks
SEPTEMBER 4, 2023
We are thrilled to announce great enhancements to onboard more workloads to Unity Catalog clusters in shared access mode, Databricks' highly efficient, secure.

databricks
MAY 1, 2023
This blog was co-authored by Elia Florio, Sr. Director of Detection & Response at Databricks and Florian Roth and Marius Bartholdy, security researchers.
databricks
MAY 11, 2023
Introduction This blog is part of our Admin Essentials series, where we'll focus on topics important to those managing and maintaining Databricks environments.

databricks
FEBRUARY 27, 2023
Ray is a prominent compute framework for running scalable AI and Python workloads, offering a variety of distributed machine learning tools, large-scale hyperparameter.

databricks
MARCH 19, 2024
Lilac is a scalable, user-friendly tool for data scientists to search, cluster. Today, we are thrilled to announce that Lilac is joining Databricks.

Data Science Dojo
MARCH 8, 2023
These libraries will help you with data manipulation, data analysis, and visualization. This blog lists some of the top Python libraries for data science that can help you get started. Step 3. By learning Python, you can effectively clean and manipulate data, create visualizations, and build machine-learning models.

AWS Machine Learning Blog
DECEMBER 24, 2024
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.

Data Science Dojo
SEPTEMBER 26, 2023
Learn about 33 tools to visualize data with this blog In this blog post, we will delve into some of the most important plots and concepts that are indispensable for any data scientist. Elbow curve: In unsupervised learning, particularly clustering, the elbow curve aids in determining the optimal number of clusters for a dataset.

databricks
JUNE 28, 2023
We are excited to announce Delta Lake 3.0, the next major release of the Linux Foundation open source Delta Lake Project, available in.

Towards AI
OCTOBER 19, 2024
Time Series Clustering Using Auto-Regressive Models, Moving Averages, and Nonlinear Trend Functions Photo by Ricardo Gomez Angel on Unsplash Clustering time series data, like stock prices or gene expression, is often difficult. This member-only story is on us. Upgrade to access all of Medium.

AWS Machine Learning Blog
DECEMBER 4, 2024
Solution overview Implementing the solution consists of the following high-level steps: Set up your environment and the permissions to access Amazon HyperPod clusters in SageMaker Studio. You can now use SageMaker Studio to discover the SageMaker HyperPod clusters, and view cluster details and metrics.

Hacker News
NOVEMBER 24, 2024
Drawing from Kuaishou's experience in implementing cloud-native Redis at scale, this blog delves into practical solutions and critical considerations for managing stateful services in Kubernetes environments.

NOVEMBER 27, 2024
The CloudFormation template provisions the following components An Aurora MySQL provisioned cluster (source) An Amazon Redshift Serverless data warehouse (target) Zero-ETL integration between the source (Aurora MySQL) and target (Amazon Redshift Serverless) To create your resources: Sign in to the console.

AWS Machine Learning Blog
SEPTEMBER 18, 2024
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.

AWS Machine Learning Blog
NOVEMBER 26, 2024
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.

Data Science Dojo
MARCH 8, 2024
This blog delves into a detailed comparison between the two data management techniques. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process. A file records vectors that belong to each cluster.

AWS Machine Learning Blog
APRIL 22, 2024
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
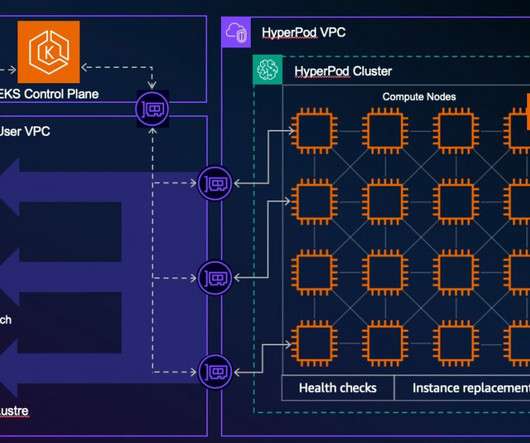
JUNE 4, 2025
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
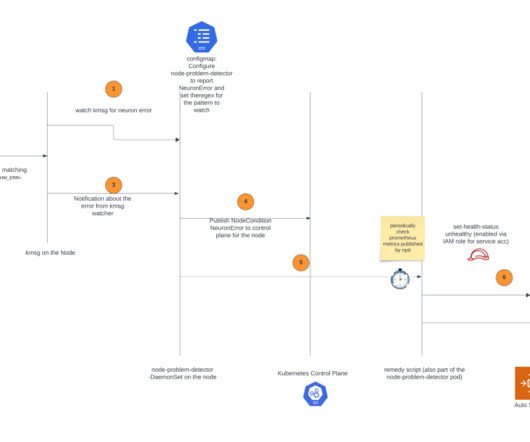
AWS Machine Learning Blog
JULY 25, 2024
Solution overview The solution is based on the node problem detector and recovery DaemonSet, a powerful tool designed to automatically detect and report various node-level problems in a Kubernetes cluster. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. #
Towards AI
SEPTEMBER 3, 2024
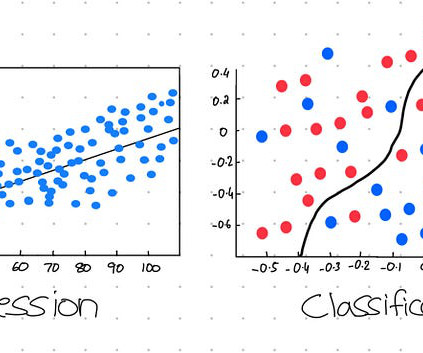
We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. The black line running through the data points is the regression line, which represents the… Read the full blog for free on Medium. I’m trying out a new thing: I draw illustrations of graphs, etc., Join thousands of data leaders on the AI newsletter.
AWS Machine Learning Blog
OCTOBER 16, 2024
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),

AWS Machine Learning Blog
MARCH 3, 2025
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.

Towards AI
NOVEMBER 1, 2024
Key Details: Meta is training Llama 4 on a massive setup with over 100,000 H100 GPUs, one of the largest AI clusters reported, aiming for faster and more capable models than ever.The new Llama 4 will introduce advanced capabilities like expanded memory, support for multiple data types, and seamless third-party integrations.AI
Hacker News
FEBRUARY 5, 2024
In this blog post, we'll do a deep-dive into a simple trick that can reduce BigQuery costs by orders of magnitude. Specifically, we'll explore how clustering (similar to indexing in BigQuery world) large tables can significantly impact costs.

Dataversity
APRIL 16, 2025
Artificial intelligence is changing everything and its impact on high availability (HA) clustering is no exception. The way in which AI and HA are coming together is making clusters more resilient, self-sustaining, and increasingly smarter at handling workloads.

AWS Machine Learning Blog
OCTOBER 24, 2024
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
AWS Machine Learning Blog
APRIL 17, 2024
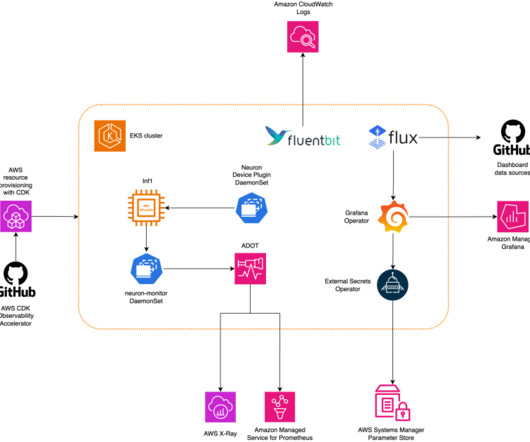
This post walks you through the Open Source Observability pattern for AWS Inferentia , which shows you how to monitor the performance of ML chips, used in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, with data plane nodes based on Amazon Elastic Compute Cloud (Amazon EC2) instances of type Inf1 and Inf2.

Hacker News
DECEMBER 9, 2023
In this blog post, we explore Spotify's journey from using the Fisher-Yates shuffle to a more sophisticated song shuffling algorithm that prevents clustering of tracks by the same artist. We then connect this challenge to Fibonacci hashing, and propose a novel, evenly distributed artist shuffling method.

Data Science Dojo
FEBRUARY 1, 2023
In this blog, we will explore how to optimize performance and reduce costs when using dedicated SQL pools in Azure Synapse Analytics. A clustered column store index is created on a table with a clustered column store architecture. DWUs (Data Warehouse Units) can customize resources and optimize performance and costs.

AWS Machine Learning Blog
APRIL 10, 2025
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.

Dataconomy
FEBRUARY 12, 2025
Deborah Turness, CEO of BBC News and Current Affairs, noted in a blog post that while AI offers “endless opportunities,” developers are “playing with fire,” raising concerns that AI-distorted headlines could cause real-world harm.

AWS Machine Learning Blog
DECEMBER 18, 2024
During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed. The integration of Amazon S3 and the SageMaker HyperPod cluster exemplifies the power of the AWS ecosystem, where various services work together seamlessly to support complex workflows.

AWS Machine Learning Blog
APRIL 2, 2025
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. A Ray cluster consists of a single head node and a number of connected worker nodes. Ray clusters and Kubernetes clusters pair well together.
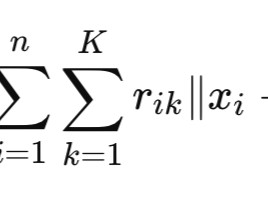
Towards AI
APRIL 28, 2025
In this second part of the Unsupervised Learning series, lets take a closer look at these three algorithms not just from a technical view, but by understanding the story behind their formulas.Because at the heart of every clustering strategy, its the measurement of similarity that makes all the difference. Or because they have the same job?Or
AWS Machine Learning Blog
JANUARY 30, 2025
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.

AWS Machine Learning Blog
NOVEMBER 22, 2024
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
AWS Machine Learning Blog
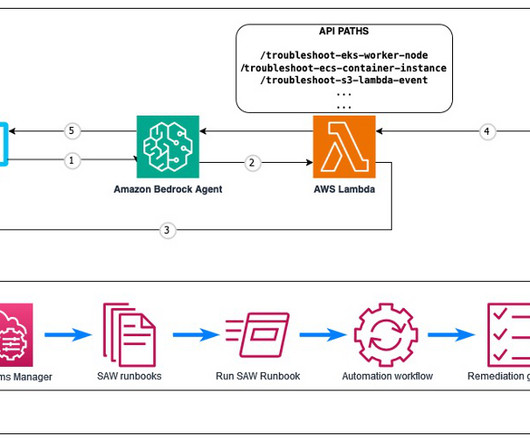
MARCH 20, 2025
Solution overview Although the solution is versatile and can be adapted to use a variety of AWS Support Automation Workflows, we focus on a specific example: troubleshooting an Amazon Elastic Kubernetes Service (Amazon EKS) worker node that failed to join a cluster. For example, Why isnt my EKS worker node joining the cluster?

Analytics Vidhya
APRIL 11, 2023
This blog post introduces a series of upcoming […] The post Unleash Your Data Insights: Learn from the Experts in Our DataHour Sessions appeared first on Analytics Vidhya. Introduction Analytics Vidhya DataHour is designed to provide valuable insights and knowledge to individuals looking to build a career in the data-tech industry.

Towards AI
JANUARY 29, 2025
clustering, dimensionality reduction)Model Evaluation and SelectionData Preprocessing and Feature Engineering With a simple and consistent API, Scikit-learn is widely regarded as the go-to library for fast prototyping and efficient deployment of machine learning models. Scikit-learn is an open-source machine learning library built on Python.
AWS Machine Learning Blog
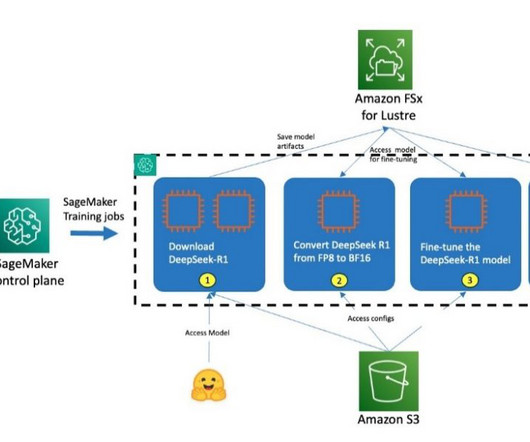
MAY 14, 2025
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. Alternatively, you can also use the AWS CloudFormation template provided in the Own Account workshop and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.

Expert insights. Personalized for you.
We have resent the email to
Are you sure you want to cancel your subscriptions?





Let's personalize your content