This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Verify the data load by running a select statement: select count (*) from sales.total_sales_data; This should return 7,991 rows. The following screenshot shows the database table schema and the sample data in the table. She has experience across analytics, bigdata, ETL, cloud operations, and cloud infrastructure management.
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
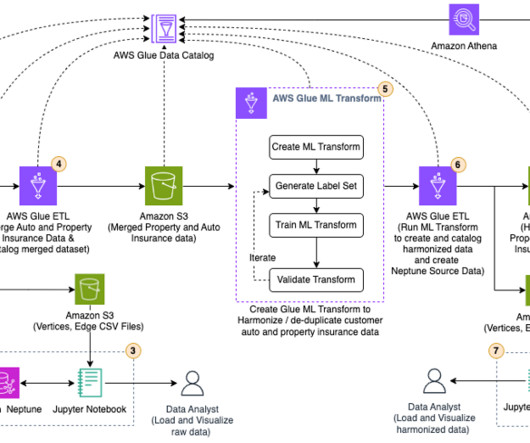
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
The ORC and Parquet are columnal storage and they are famous in the BigData world because of their efficient storage. First things first, load the sample data into the S3 bucket. The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost?
The generated images can also be downloaded as PNG or JPEG files. In the above instruction, you learned how the data explorer works with different visualizations. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. BigData Architect. He works based in Tokyo, Japan.
With Tableau’s new and updated Azure connectivity you can gain more value from your data investments by adding seamless and powerful analytics to your Azure stack. Azure Data Lake Storage Gen2. Data Lakes have become a staple of enterprise data strategies. They offer a low-cost, bigdata storage solution.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
With Tableau’s new and updated Azure connectivity you can gain more value from your data investments by adding seamless and powerful analytics to your Azure stack. Azure Data Lake Storage Gen2. Data Lakes have become a staple of enterprise data strategies. They offer a low-cost, bigdata storage solution.
Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Pricing It is free to use and is licensed under Apache License Version 2.0.
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications. Unstructured.io
The Data Lake Admin has an AWS Identity and Access Management (IAM) admin role and is a Lake Formation administrator responsible for managing user permissions to catalog objects using Lake Formation. The Data Warehouse Admin has an IAM admin role and manages databases in Amazon Redshift. Choose Churn_Analysis for EMR-S Application.
Pixlr Pixlr s AI-powered online editor offers advanced image manipulation without requiring software downloads. Best AI apps for data analysis In the era of bigdata , AI-driven analytics tools help businesses and researchers process, visualize, and extract insights from massive datasets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content