This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and bigdata frameworks (Hadoop, Apache Spark).
BigData as a Service (BDaaS) has revolutionized how organizations handle their data, transforming vast amounts of information into actionable insights. By leveraging cloud computing technologies, businesses gain access to advanced tools and resources that simplify data management and processing.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
- a beginner question Let’s start with the basic thing if I talk about the formal definition of Data Science so it’s like “Data science encompasses preparing data for analysis, including cleansing, aggregating, and manipulating the data to perform advanced data analysis” , is the definition enough explanation of data science?
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Query the vector data store You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
This data captures the sequence of web pages a user visits, how long they stay on each page, and the actions they take during their session. By examining clickstream data, businesses can discern patterns in user behavior, helping them tailor their offerings and enhance user satisfaction.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
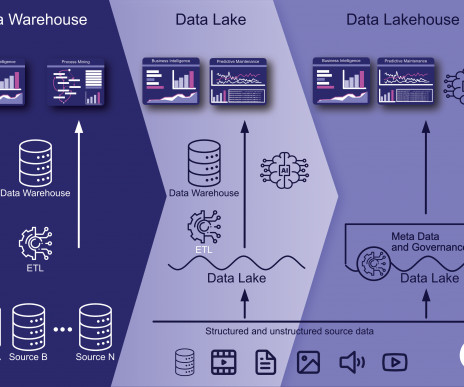
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Acquire essential skills to efficiently preprocess data before it enters the data pipeline. Hadoop: The Definitive Guide by Tom White This comprehensive guide delves into the Apache Hadoop ecosystem, covering HDFS, MapReduce, and bigdata processing.
Theres a lot of heavy lifting on the data infrastructure that they need to have in place. Its similar to BigData, where the enterprise took longer to optimize their stack. 7:19 : Can you describe why enterprises need to modernize their data stack? Theres a lot of complexity in data and how data is handled.
The challenges of a monolithic data lake architecture Data lakes are, at a high level, single repositories of data at scale. Data may be stored in its raw original form or optimized into a different format suitable for consumption by specialized engines. Comprehensive data security and data governance (i.e.
Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, Machine Learning, data mining, bigdata technologies, and visualisation. What does a typical Data Science syllabus cover?
It is a process for moving and managing data from various sources to a central data warehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
Tools such as Matplotlib, Seaborn, and Tableau may help you in creating useful visualisations that make challenging data more readily available and understandable to others. It is critical for knowing how to work with huge data sets efficiently. Yes, kids, especially teenagers can be the ideal starting age for learning Data Science.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
Data fabric is now on the minds of most data management leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The data catalog is a foundational layer of the data fabric. ” 1.
BigData tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. BigData wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit BigData beinahe synonym gesetzt.
Aber Moment mal, was ist eigentlich ein Data Lakehouse? Der Artikel beginnt mit einer Definition, was ein Lakehouse ist, gibt einen kurzen geschichtlichen Abriss, wie das Lakehouse entstanden ist und zeigt, warum und wie man ein Data Lakehouse aufbauen sollte.
Definition and purpose The primary purpose of ensemble modeling is to combine multiple predictive models to maximize accuracy and minimize error rates. Technological advancements Improvements in bigdata technologies, such as Hadoop and Spark, have transformed the landscape of ensemble modeling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content