This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Bigdata management encompasses the intricate processes and technologies that organizations employ to handle vast amounts of data. As businesses increasingly rely on data to drive strategies and decisions, effective management of this information becomes essential for achieving competitive advantage and insights.
Data validation and cleansing processes: Ensuring dataquality and accuracy before it is analyzed. Design and implementation of database architectures: Setting up scalable databases that efficiently store and manage data.
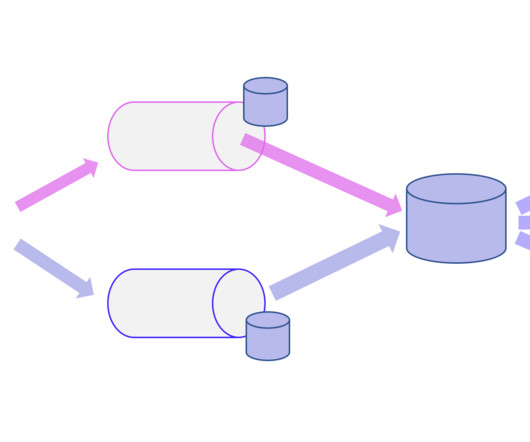
BigData Analytics stands apart from conventional data processing in its fundamental nature. In the realm of BigData, there are two prominent architectural concepts that perplex companies embarking on the construction or restructuring of their BigData platform: Lambda architecture or Kappa architecture.
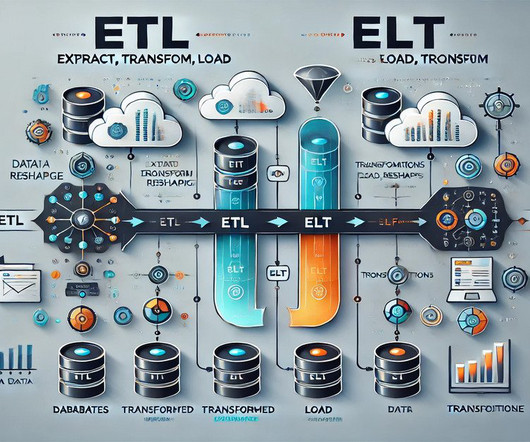
ETL (Extract, Transform, Load) is a crucial process in the world of data analytics and business intelligence. In this article, we will explore the significance of ETL and how it plays a vital role in enabling effective decision making within businesses. What is ETL? Let’s break down each step: 1.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. It provides a scalable and fault-tolerant ecosystem for bigdata processing.
The magic of the data warehouse was figuring out how to get data out of these transactional systems and reorganize it in a structured way optimized for analysis and reporting. Then came BigData and Hadoop! The bigdata boom was born, and Hadoop was its poster child. A data lake!
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. However, data engineering is not without its challenges.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
The efficiency of ETL integration can make or break the rest of your data management workflow. Want to get the most from your ETL processes? Keep reading for high-performance ETL best practices. 8 ETL best practices For optimum integration results, here’s eight of our best tips.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Bigdata analytics: Bigdata analytics is designed to handle massive volumes of data from various sources, including structured and unstructured data. Bigdata analytics is essential for organizations dealing with large-scale data, such as social media platforms, e-commerce giants, and scientific research.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
It is ideal for handling unstructured or semi-structured data, making it perfect for modern applications that require scalability and fast access. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles BigData. It integrates well with various data sources, making analysis easier.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
The storage and processing of data through a cloud-based system of applications. Master data management. The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). Data transformation. Microsoft Azure.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring dataquality and integrity.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
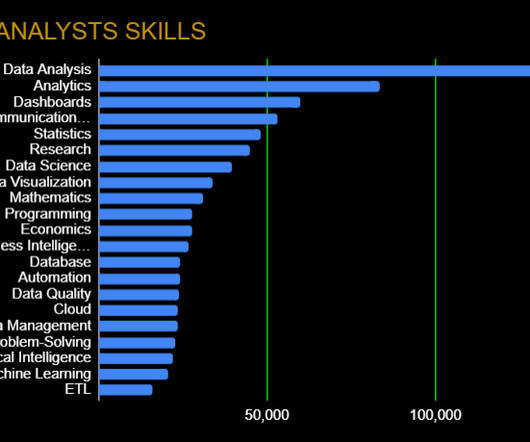
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Raw DataData warehouses emerged several decades ago as a means of combining, harmonizing, and preprocessing data in preparation for advanced analytics. A data warehouse implies a certain degree of preprocessing, or at the very least, an organized and well-defined data model. The post Data Warehouse vs.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Run the notebooks The sample code for this solution is available on GitHub.
Such growth makes it difficult for many enterprises to leverage bigdata; they end up spending valuable time and resources just trying to manage data and less time analyzing it. What are the big differentiators between HPCC Systems and other bigdata tools? Spark is indeed a popular bigdata tool.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. DataQuality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. They store structured data in a format that facilitates easy access and analysis.
With the year coming to a close, many look back at the headlines that made major waves in technology and bigdata – from Spark to Hadoop to trends in data science – the list could go on and on. However, most are only deployed over one data store (Hadoop or other various backends).
Data scientists can explore, experiment, and derive valuable insights without the constraints of a predefined structure. This capability empowers organizations to uncover hidden patterns, trends, and correlations in their data, leading to more informed decision-making. What Is a Data Warehouse? What is meant by Data Lake?
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. Let’s look at some example transforms.
In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today's digital world.
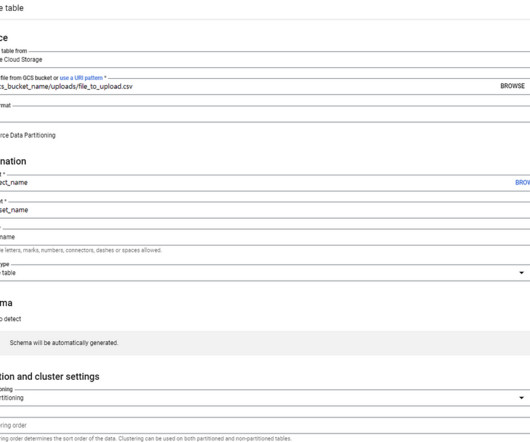
[link] Tables The table in GCP BigQuery is a collection of rows and columns that can store and manage massive amounts of data. It’s a managed, cloud-based service that’s designed to handle bigdata processing with ease. You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
(See Gartner’s “ How DataOps Amplifies Data and Analytics Business Value ”). On the process side, DataOps is essentially an agile and unified approach to building data movements and transformation pipelines (think streaming and modern ETL). How can data users navigate and understand such a complex landscape predictably?
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications. Unstructured.io
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Together with the Hertie School , we co-hosted an inspiring event, Empowering in Data & Governance. The event was opened by Aliya Boranbayeva , representing Women in BigData Berlin and the Hertie School Data Science Lab , alongside Matthew Poet , representing the Hertie School. Evgeniya Panova presented doWow.tv
Their data pipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a data governance layer. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content