This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
Bigdata engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on bigdata to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, dataquality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. Implementing data security measures Data security is a critical aspect of data engineering.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “data lake.” While datawarehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between Data Lakes and DataWarehouses appeared first on DATAVERSITY.
There are countless examples of bigdata transforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about data visualization and its role in the bigdata movement.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
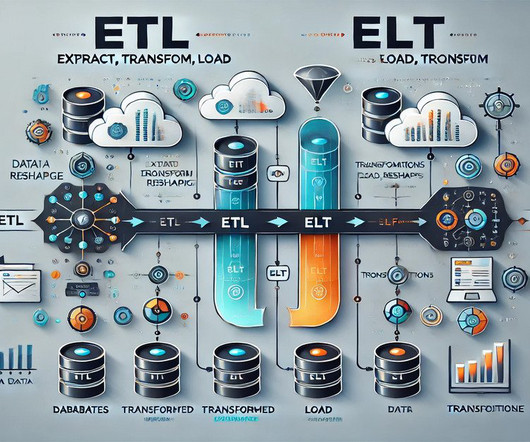
ETL is a three-step process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target database or datawarehouse. Extract The extraction phase involves retrieving data from diverse sources such as databases, spreadsheets, APIs, or other systems.
It is ideal for handling unstructured or semi-structured data, making it perfect for modern applications that require scalability and fast access. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles BigData. It integrates well with various data sources, making analysis easier.
Bigdata analytics: Bigdata analytics is designed to handle massive volumes of data from various sources, including structured and unstructured data. Bigdata analytics is essential for organizations dealing with large-scale data, such as social media platforms, e-commerce giants, and scientific research.
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets. Metadata makes the task a lot easier.
It is a crucial data integration process that involves moving data from multiple sources into a destination system, typically a datawarehouse. This process enables organisations to consolidate their data for analysis and reporting, facilitating better decision-making. ETL stands for Extract, Transform, and Load.
This experience helped me to improve my Python skills and get more practical experience working with bigdata. I am also a judge in several international hackathons, including the United Nations BigData Hackathon , where I evaluated 18 different teams based on their solutions’ innovation, quality, and applicability.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring dataquality and integrity.
With the year coming to a close, many look back at the headlines that made major waves in technology and bigdata – from Spark to Hadoop to trends in data science – the list could go on and on. 2016 will be the year of the “logical datawarehouse.”
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Bigdata analytics, IoT, AI, and machine learning are revolutionizing the way businesses create value and competitive advantage. Organizations have come to understand that they can use both internal and external data to drive tremendous business value. Secure data exchange takes on much greater importance.
It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data. In a Hadoop cluster, data stored in the Hadoop Distributed File System (HDFS), which spreads the data across the nodes.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. In the extraction phase, the data is collected from various sources and brought into a staging area.
Additional considerations Though the potential of this approach is significant, there are several challenges to consider: Dataquality High-quality, diverse input data is key to effective model performance. He is focused on bigdata, data lakes, streaming and batch analytics services, and generative AI technologies.
For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization. Ensuring dataquality is made easier as a result.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Also Read: Top 10 Data Science tools for 2024. What is ETL?
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure dataquality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of bigdata and self-service analytics.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a datawarehouse or data lake. Data Lakes: These store raw, unprocessed data in its original format.
And, it recently received the 2018 Digital Innovation Award for BigData from Ventana Research. Data is not something that’s easy to consume, it’s not something easy to recognize. We need more that makes it easy to identify dataquality, data issues, et cetera. Got a great conversation today.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a datawarehouse or a data lake. This ensures that the data is accurate, consistent, and reliable.
Data Modeling These are simple diagrams of the system and the data stored in it. It helps you to view how the data flows through the system. It includes customer data, partner information and others. DataQuality Management The quality of data plays a significant role in defining the effectiveness of data insights.
The right data integration solution helps you streamline operations, enhance dataquality, reduce costs, and make better data-driven decisions. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
Data Warehousing and ETL Processes What is a datawarehouse, and why is it important? A datawarehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content