This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
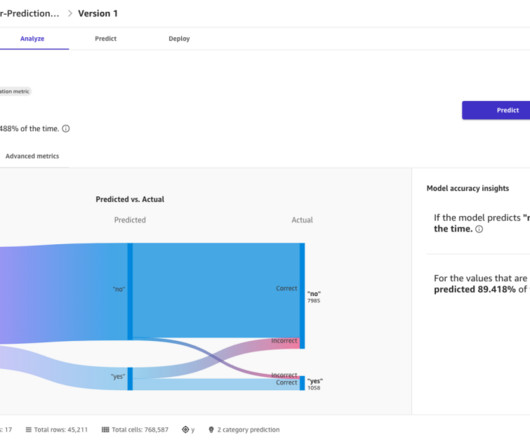
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. You can review the generated Data Quality and Insights Report to gain a deeper understanding of the data, including statistics, duplicates, anomalies, missing values, outliers, target leakage, data imbalance, and more.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and bigdata frameworks (Hadoop, Apache Spark).
As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. But here is a problem: While pySpark syntax is straightforward and very easy to follow, it can be readily confused with other common libraries for datawrangling. Let’s get started.
There has been an explosion of data, from social and mobile data to bigdata, that is fueling new ways to understand and improve customer experience. Davis will discuss how datawrangling makes the self-service analytics process more productive. We are entering an era of self-service analytics.
Data Analysts need deeper knowledge on SQL to understand relational databases like Oracle, Microsoft SQL and MySQL. Moreover, SQL is an important tool for conducting DataPreparation and DataWrangling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content