This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Extract, Transform, Load (ETL) The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into data warehouses, typically utilizing batch processing. This approach allows organizations to work with large volumes of data efficiently.
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
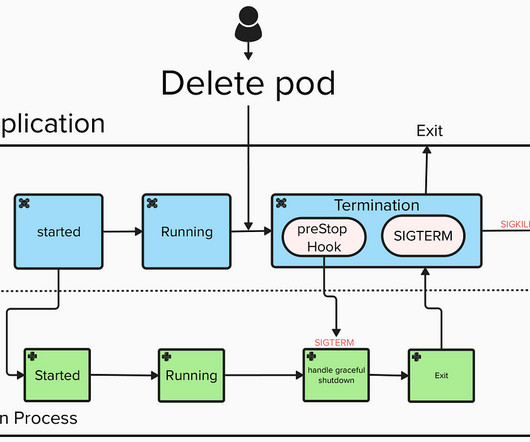
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. What happens when a user or system administrator needs to kill a job mid-execution?
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
Musani emphasized the massive scale: “More than a million users doing 30,000 queries a day…that’s massive things happening on such rich data.” Unified datapipelines connect the supply chain to the store floor. As Musani explains: “We have built element in a way where it makes it agnostic to different llms as well, right? “We
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. Oh, also, I'm great at writing documentation.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
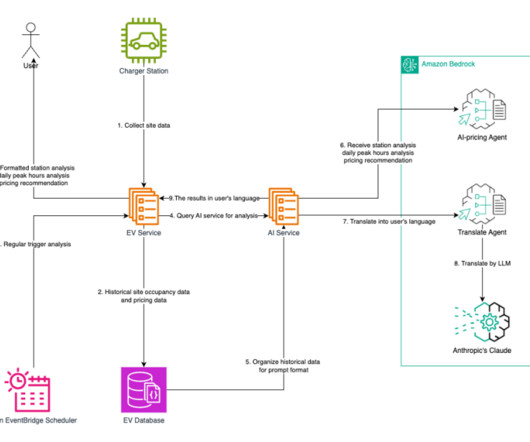
Amazon Elastic Kubernetes Service (Amazon EKS) retrieves data from Amazon DocumentDB , processes it, and invokes Amazon Bedrock Agents for reasoning and analysis. This structured datapipeline enables optimized pricing strategies and multilingual customer interactions.
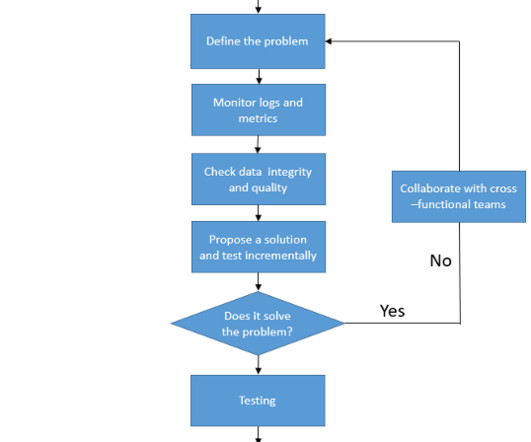
Bigdatapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets. A document is susceptible to change.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture.
Once your information is organized, a data observability tool can take your data quality efforts to the next level by managing data drift or schema drift before they break your datapipelines or affect any downstream analytics applications. What Does a Data Catalog Do?
It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. However, these tools have functional gaps for more advanced data workflows. Git LFS requires a LFS server to work.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. Bias can also find its way into a model’s outputs long after deployment.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Read More: Advanced SQL Tips and Tricks for Data Analysts.
In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organizations to detect anomalies, troubleshoot issues, and maintain datapipelines effectively. This involves creating data dictionaries, documentation, and metadata.
Unified Data Services: Azure Synapse Analytics combines bigdata and data warehousing, offering a unified analytics experience. Azure’s global network of data centres ensures high availability and performance, making it a powerful platform for Data Scientists to leverage for diverse data-driven projects.
Court documents and case dockets were stored on a mainframe system, where they were inaccessible to the public at large. Precisely helped court officials to implement a streaming datapipeline to replicate that information to a cloud data platform, where it was available for web developers to publish online.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. A cloud environment with such features will support collaboration across departments and across common data types, including csv, JSON, XML, AVRO, Parquet, Hyper, TDE, and more. Collaboration and governance.
It is particularly popular among data engineers as it integrates well with modern datapipelines (e.g., Source: [link] Monte Carlo is a code-free data observability platform that focuses on data reliability across datapipelines. It integrates well with modern data engineering pipelines (e.g.,
Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? What Are the Benefits of a Modern Data Stack?
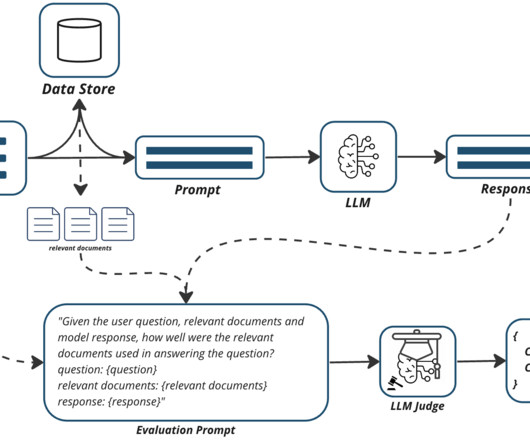
The hype around generative AI has shifted the industry narrative overnight from the bigdata era of “every company is a data company” to the new belief that “every company is an AI company.” This metric would be used to decide whether more or less documents are needed to provide relevant context.
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. SIMT describes processors that are able to operate on data vectors and arrays (as opposed to just scalars), and therefore handle bigdata workloads efficiently.
To support these diverse data sources, semi-structured data formats have become popular standards for transporting and storing data. What are Supported File Formats for Semi-structured Data Various semi-structured datasets, including JSON, Avro, Parquet, Orc, and XML, have emerged with the rise of bigdata and IoT.
Classification techniques, such as image recognition and document categorization, remain essential for a wide range of industries. Soft Skills Technical expertise alone isnt enough to thrive in the evolving data science landscape. Employers increasingly seek candidates with strong soft skills that complement technical prowess.
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. These indexes continuously accumulate documents.
We reuse the datapipelines described in this blog post. Clinical data The data is stored in CSV format as shown in the following table. Icons show each stage: document icons for DICOM files, S3 bucket symbol, lung CT scan images, segmented tumor view, and tabular data representing extracted features.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content