This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Extract, Transform, Load (ETL) The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into data warehouses, typically utilizing batch processing. This approach allows organizations to work with large volumes of data efficiently.
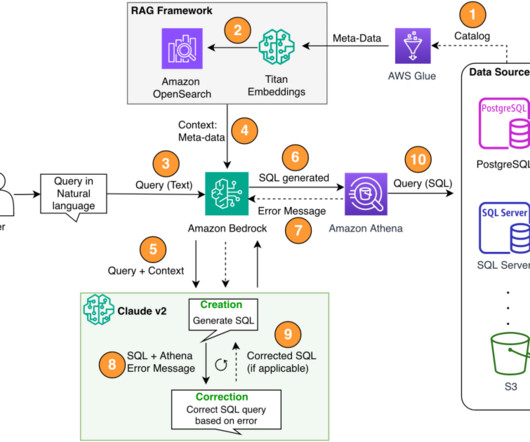
Search solutions in modern bigdata management must facilitate efficient and accurate search of enterprise data assets that can adapt to the arrival of new assets. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
We spend half a day a week reading documentation and doing nothing else, and another full day coaching the team on cutting edge tech (how to design, build, train, deploy ai models). It is a toolbox for web engineers and application developers who need a painless way to render, edit and process documents. We invest a lot in our team.
He is focused on bigdata, datalakes, streaming and batch analytics services, and generative AI technologies. Dhara Vaishnav is Solution Architecture leader at AWS and provides technical advisory to enterprise customers to use cutting-edge technologies in generative AI, data, and analytics.
To define the term, let’s first say that structured data includes spreadsheets with their formalized rows and columns, “form-based” data resources where we know the fields in a document and so we know what values to expect… and of course relational databases, the purest form of an ordered and structured data repository.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
LakeFS Most bigdata storage solutions such as Azure, Google cloud storage, and Amazon S3 have good performance, cost-effective, and have good connectivity with other tooling. However, these tools have functional gaps for more advanced data workflows. Git LFS requires a LFS server to work.
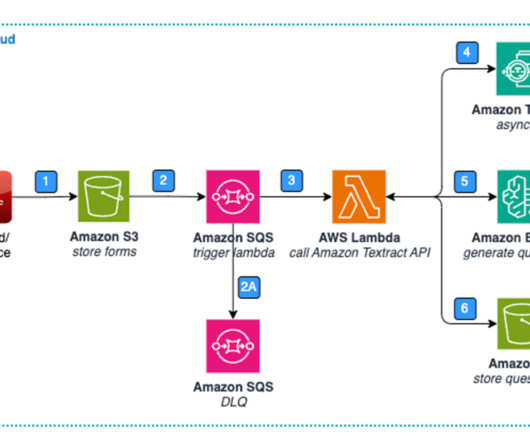
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of bigdata and self-service analytics.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. About the Authors Sanjeeb Panda is a Data and ML engineer at Amazon.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
To fully realize data’s value, organizations in the travel industry need to dismantle data silos so that they can securely and efficiently leverage analytics across their organizations. What is bigdata in the travel and tourism industry? Using Alation, ARC automated the data curation and cataloging process. “So
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
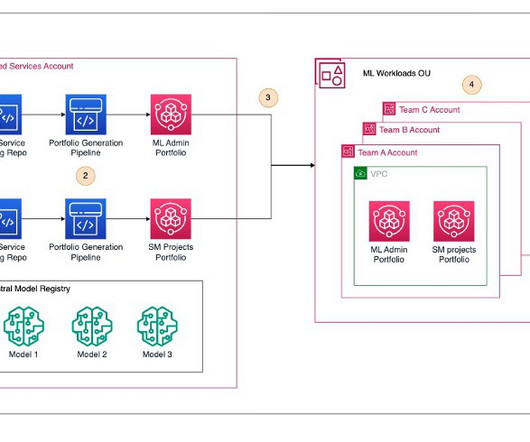
Data scientists Perform data analysis, model development, model evaluation, and registering the models in a model registry. Governance officer Review the models performance including documentation, accuracy, bias and access, and provide final approval for models to be deployed.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
A cloud environment with such features will support collaboration across departments and across common data types, including csv, JSON, XML, AVRO, Parquet, Hyper, TDE, and more. It’s More Important to Know What Your Data Means Than Where It Is. Pushing data to a datalake and assuming it is ready for use is shortsighted.
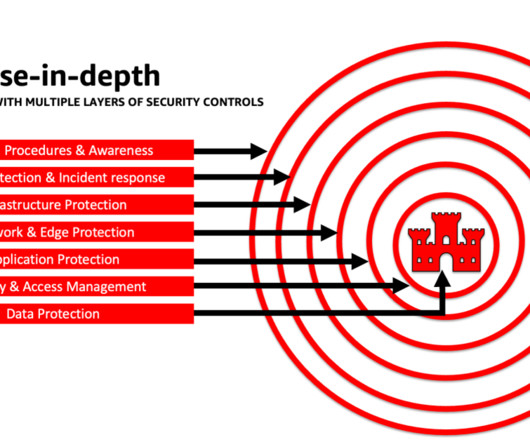
Create an incident response plan , a written document that details how you will respond before, during and after a suspected or confirmed security threat. Secure databases in the physical data center, bigdata platforms and the cloud. In 2022, it took an average of 277 days to identify and contain a data breach.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Data Architect, DataLake at AWS.
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
These organizations have a huge demand for lakehouse solutions that combine the best of data warehouses and datalakes to simplify data management with easy access to all data from their preferred engines. Stefano Sandon is a Senior BigData Specialist Solution Architect at Amazon Web Services (AWS).
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. Data must be preprocessed to enable semantic search during inference.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







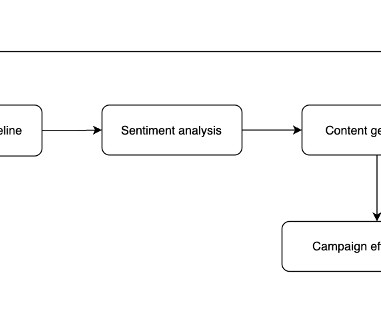









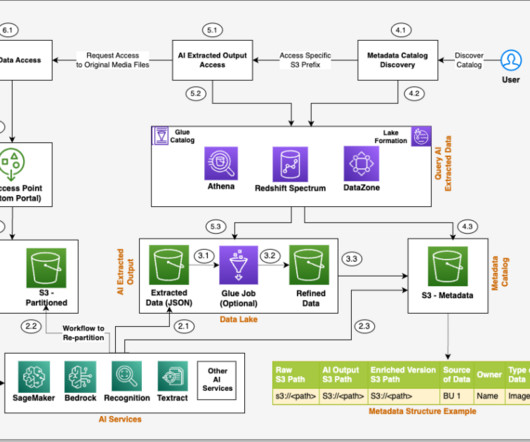
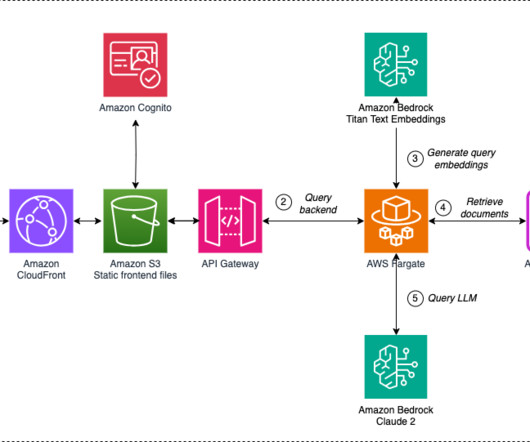

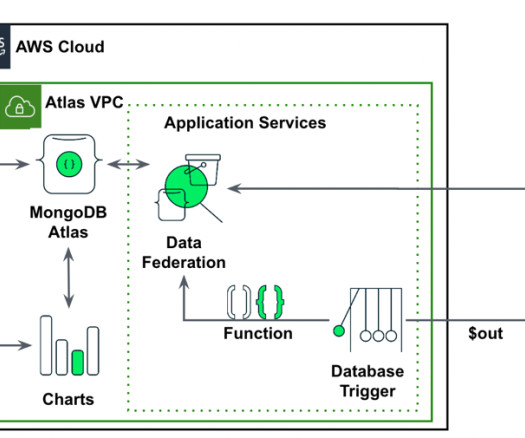


















Let's personalize your content