This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
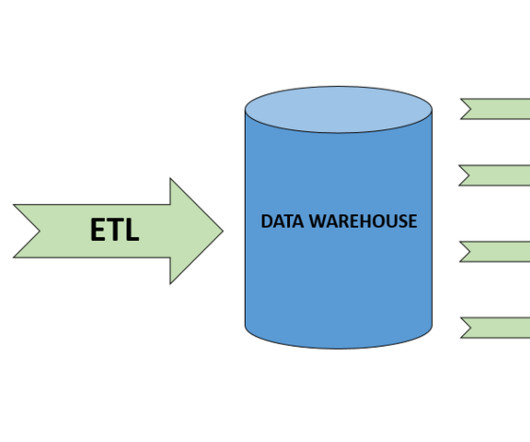
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. They must also ensure that data privacy regulations, such as GDPR and CCPA , are followed.
The magic of the data warehouse was figuring out how to get data out of these transactional systems and reorganize it in a structured way optimized for analysis and reporting. Then came BigData and Hadoop! The bigdata boom was born, and Hadoop was its poster child.
Set up an Aurora MySQL database Complete the following steps to create an Aurora MySQL database to host the structured sales data: On the Amazon RDS console, choose Databases in the navigation pane. Under Settings , enter a name for your database cluster identifier. Delete the Aurora MySQL instance and Aurora cluster.
Optimized for analytical processing, it uses specialized data models to enhance query performance and is often integrated with business intelligence tools, allowing users to create reports and visualizations that inform organizational strategies. Security features include data encryption and access control.
Because embeddings are an important source of data for NLP models in general and generative AI solutions in particular, we need a way to measure whether our embeddings are changing over time (drifting). Then we use K-Means to identify a set of cluster centers.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
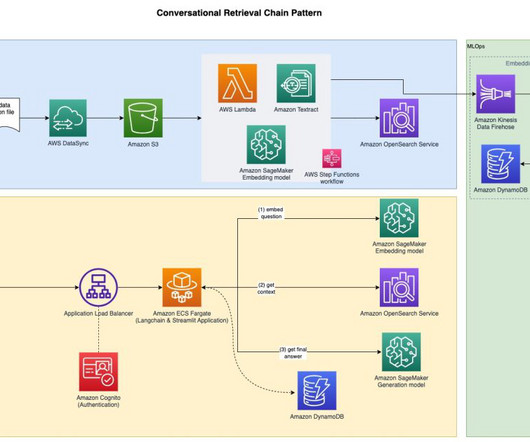
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
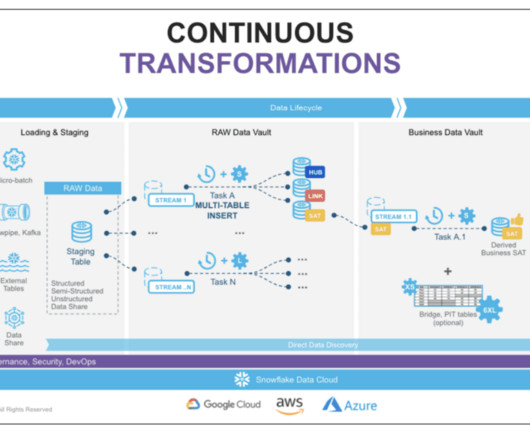
In this blog, we explore best practices and techniques to optimize Snowflake’s performance for data vault modeling , enabling your organizations to achieve efficient data processing, accelerated query performance, and streamlined ETL workflows. However, joining tables using a hash key can take longer than a sequential key.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. The outputs of this template are as follows: An S3 bucket for the data lake.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. While both handle vast datasets across clusters, they differ in approach. What is Apache Spark?
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
· Hive Execution Engine It executes the generated query plans on the Hadoop cluster. Thus, making it easier for analysts and data scientists to leverage their SQL skills for BigData analysis. This compilation process optimizes the query plan to leverage parallel processing and minimize data movement.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Its visual interface allows users to design complex ETL workflows with ease.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. He is passionate about machine learning engineering, distributed systems, and big-data technologies. Every Airflow task calls Amazon ECS tasks with some overrides.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. Data Quality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. They store structured data in a format that facilitates easy access and analysis.
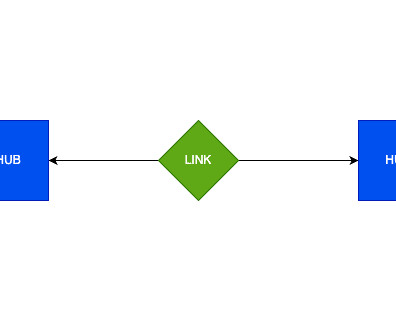
Unlike traditional data warehousing solutions, Snowflake brings critical features like Data Sharing , Snowpipe, Streams, and Time-Travel to the enterprise data architecture space. What is Data Vault Modeling? By combining the Snowflake Data Cloud with a Data Vault 2.0
Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Multimodal embeddings help combine unstructured data from various sources in data warehouses and ETL pipelines.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Server update locks the entire cluster. It supports multiple file formats.
I would perform exploratory data analysis to understand the distribution of customer transactions and identify potential segments. Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. What approach would you take?
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications. Unstructured.io
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
The Data Lake Admin has an AWS Identity and Access Management (IAM) admin role and is a Lake Formation administrator responsible for managing user permissions to catalog objects using Lake Formation. The Data Warehouse Admin has an IAM admin role and manages databases in Amazon Redshift.
It secures your data in the lakehouse by defining fine-grained permissions, which are consistently applied across all analytics and ML tools and engines. You can bring data from operational databases and applications into your lakehouse in near real time through zero-ETL integrations. config(f'spark.sql.catalog.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content