This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
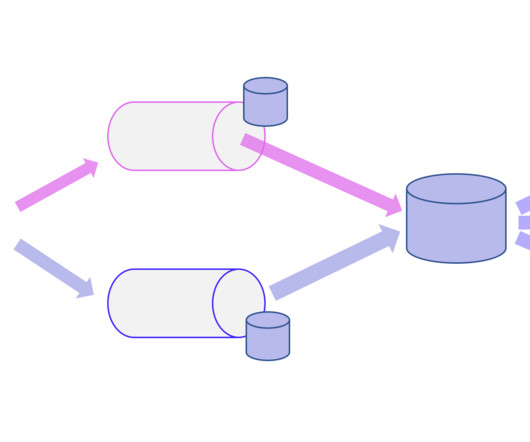
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
BigData Analytics stands apart from conventional data processing in its fundamental nature. In the realm of BigData, there are two prominent architectural concepts that perplex companies embarking on the construction or restructuring of their BigData platform: Lambda architecture or Kappa architecture.
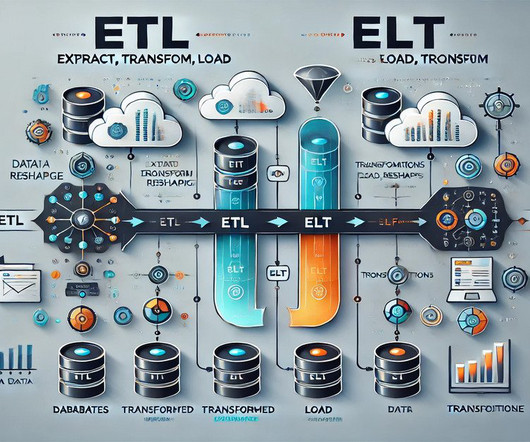
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
In the contemporary age of BigData, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures? appeared first on Data Science Blog.
She has experience across analytics, bigdata, ETL, cloud operations, and cloud infrastructure management. Data Engineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Process Mining demands BigData in 99% of the cases, releasing bad developed extraction jobs will end in big cost chunks down the value stream. Process Mining – Data Extraction The data extraction for process mining should be well planed and match the data strategy of the organization.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed data engine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Data Science You heard this term most of the time all over the internet, as well this is the most concerning topic for newbies who want to enter the world of data but don’t know the actual meaning of it. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ Data Science ’.
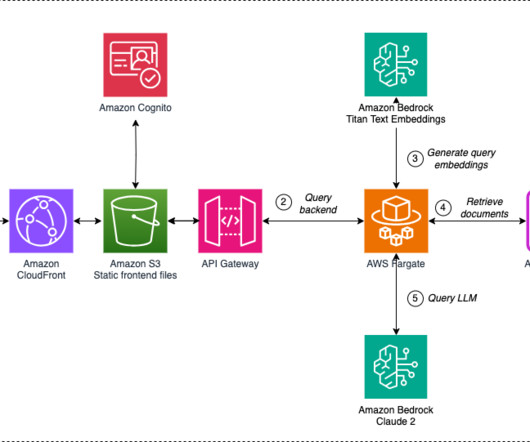
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
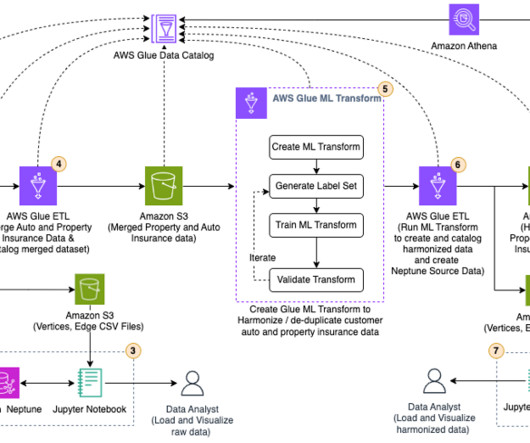
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
In this blog post, we’ll examine what is data warehouse architecture and what exactly constitutes good data warehouse architecture as well as how you can implement one successfully without needing some kind of computer science degree!
However, to harness the full potential of Snowflake’s performance capabilities, it is essential to adopt strategies tailored explicitly for data vault modeling. Hash keys provide all key types’ best data load performance, consistency, and audibility.
If you’ve been watching how Snowflake Data Cloud has been growing and changing over the years, you’ll see that two tools have made very large impacts on the Modern Data Stack: Fivetran and dbt. In short, ELT exemplifies the data strategy required in the era of bigdata, cloud, and agile analytics.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
Data engineering is all about collecting, organising, and moving data so businesses can make better decisions. Handling massive amounts of data would be a nightmare without the right tools. In this blog, well explore the best data engineering tools that make data work easier, faster, and more reliable.
Publishing used to be the province of big newspapers. With blogs, anyone can now write and distribute an article and with message boards anyone can post an advertisement. Business Intelligence used to require months of effort from BI and ETL teams. Today, however, the gal that knows the data could be half-way around the world.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Or maybe you are interested in an individual data strategy ? The post How Cloud Data Platforms improve Shopfloor Management appeared first on Data Science Blog. Then get in touch with me!
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Its visual interface allows users to design complex ETL workflows with ease.
A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means.
But raw data alone isn’t enough to gain valuable insights. This is where data warehouses come in – powerful tools designed to transform raw data into actionable intelligence. This blog delves into the world of data warehouses, exploring their functionality, key features, and the latest innovations.
Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. Hive is a data warehousing infrastructure built on top of Hadoop. Here comes the role of Hive in Hadoop. What is Hadoop ?
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química. He has more than 8 years of experience with bigdata and machine learning projects in financial, retail, energy, and chemical industries. The following diagram illustrates this architecture.
Introduction Business Intelligence (BI) architecture is a crucial framework that organizations use to collect, integrate, analyze, and present business data. This architecture serves as a blueprint for BI initiatives, ensuring that data-driven decision-making is efficient and effective.
As businesses increasingly rely on data-driven strategies, the global BI market is projected to reach US$36.35 The rise of bigdata, along with advancements in technology, has led to a surge in the adoption of BI tools across various sectors.
With the year coming to a close, many look back at the headlines that made major waves in technology and bigdata – from Spark to Hadoop to trends in data science – the list could go on and on. However, most are only deployed over one data store (Hadoop or other various backends). Subscribe to Alation's Blog.
Accordingly, one of the most demanding roles is that of Azure Data Engineer Jobs that you might be interested in. The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. How to Become an Azure Data Engineer?
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
Tableau, owned by Salesforce, is a leading tool for data visualization, allowing users to create interactive dashboards and reports for better data understanding and decision-making. While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics.
Data scientists can explore, experiment, and derive valuable insights without the constraints of a predefined structure. This capability empowers organizations to uncover hidden patterns, trends, and correlations in their data, leading to more informed decision-making. What Is a Data Warehouse? What is meant by Data Lake?
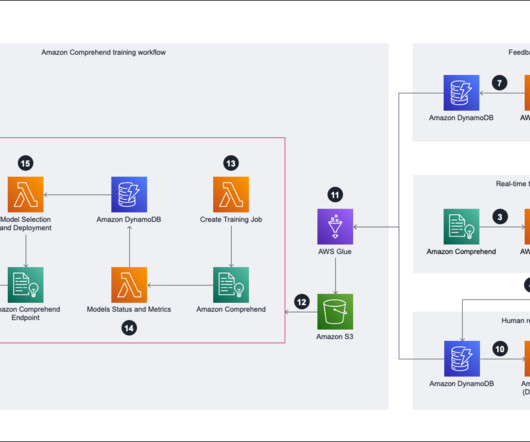
Amazon Comprehend training workflow To start the training the Amazon Comprehend model, we need to prepare the training data. When the Amazon S3 training data is ready, we can trigger AWS Step Functions as the orchestration tool to run the training job, and we pass the S3 path into the Step Functions state machine.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area.
Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Pricing It is free to use and is licensed under Apache License Version 2.0.
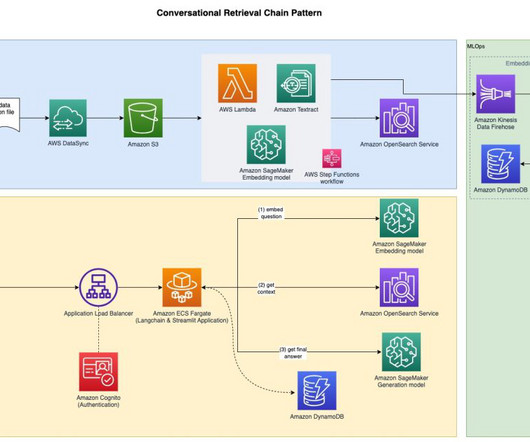
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content