This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
In the contemporary age of BigData, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
Want to create a robust datawarehouse architecture for your business? The sheer volume of data that companies are now gathering is incredible, and understanding how best to store and use this information to extract top performance can be incredibly overwhelming.
While you may think that you understand the desires of your customers and the growth rate of your company, data-driven decision making is considered a more effective way to reach your goals. The use of bigdata analytics is, therefore, worth considering—as well as the services that have come from this concept, such as Google BigQuery.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
Organisations must store data in a safe and secure place for which Databases and Datawarehouses are essential. You must be familiar with the terms, but Database and DataWarehouse have some significant differences while being equally crucial for businesses. What is DataWarehouse?
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “data lake.” While datawarehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between Data Lakes and DataWarehouses appeared first on DATAVERSITY.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
There are countless examples of bigdata transforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. BigData Architect. option("multiLine", "true").option("header",
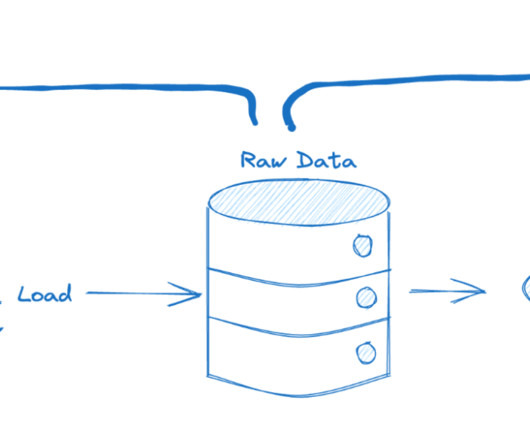
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements. Conclusion.
In a prior blog , we pointed out that warehouses, known for high-performance data processing for business intelligence, can quickly become expensive for new data and evolving workloads. To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures.
Data engineering is all about collecting, organising, and moving data so businesses can make better decisions. Handling massive amounts of data would be a nightmare without the right tools. In this blog, well explore the best data engineering tools that make data work easier, faster, and more reliable.
In fact, according in an IDC DataSphere study, IDC estimated that 10,628 exabytes (EB) of data was determined to be useful if analyzed, while only 5,063 exabytes (EB) of data (47.6%) was analyzed in 2022. How does an open data lakehouse architecture support AI? All of this supports the use of AI.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with data pipelines and orderly, efficient datawarehouses. But as bigdata continued to grow and the amount of stored information increased every […].
In this episode, James Serra, author of “Deciphering Data Architectures: Choosing Between a Modern DataWarehouse, Data Fabric, Data Lakehouse, and Data Mesh” joins us to discuss his book and dive into the current state and possible future of data architectures.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? Delta Lake became popular for making data lakes more reliable and easy to manage.
If you’ve been watching how Snowflake Data Cloud has been growing and changing over the years, you’ll see that two tools have made very large impacts on the Modern Data Stack: Fivetran and dbt. In short, ELT exemplifies the data strategy required in the era of bigdata, cloud, and agile analytics.
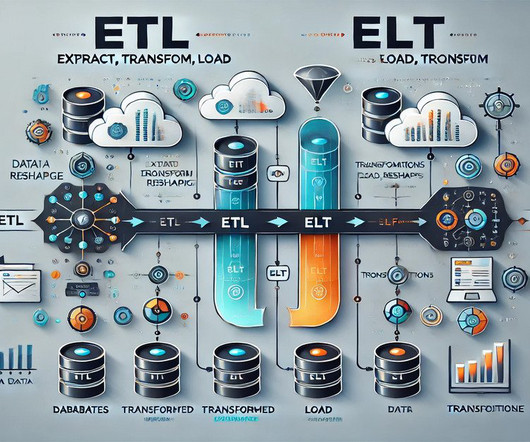
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. It ensures the data is accurate and reliable, leading to better decision-making.
This course called on the students to utilize the catalog to find and query sample data, and then to publish results into articles on the site. For the course, ‘BigData and Society’, we loaded publicly available COVID-19 data into the catalog for student use and investigation. iSchool Skills for Data Catalog Management.
As bigdata matures, the way you think about it may have to shift also. It’s no longer enough to build the datawarehouse. Self-service analytics environments are giving rise to the data marketplace. Self-service analytics environments are giving rise to the data marketplace.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Data orchestration tools. In the past, data movement was defined by ETL: extract, transform, and load.
With the year coming to a close, many look back at the headlines that made major waves in technology and bigdata – from Spark to Hadoop to trends in data science – the list could go on and on. 2016 will be the year of the “logical datawarehouse.” Subscribe to Alation's Blog.
Datawarehouses are a critical component of any organization’s technology ecosystem. The next generation of IBM Db2 Warehouse brings a host of new capabilities that add cloud object storage support with advanced caching to deliver 4x faster query performance than previously, while cutting storage costs by 34x 1.
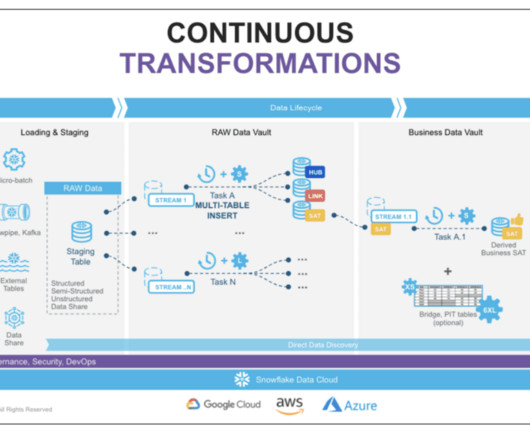
In today’s world, data-driven applications demand more flexibility, scalability, and auditability, which traditional datawarehouses and modeling approaches lack. This is where the Snowflake Data Cloud and data vault modeling comes in handy. What is Data Vault Modeling?
This was, without a question, a significant departure from traditional analytic environments, which often meant vendor-lock in and the inability to work with data at scale. Another unexpected challenge was the introduction of Spark as a processing framework for bigdata.
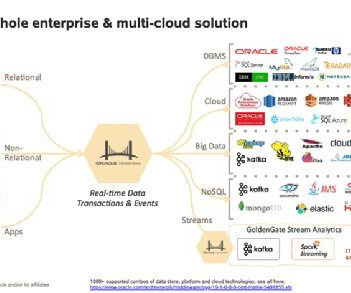
From keeping an active backup to consolidating or broadcasting data between platforms, GoldenGate is a very versatile tool that can handle many different use cases. Prerequisites In this blog, we focus on ingesting data into the Snowflake Data Cloud with GoldenGate and so we will pick up the replication process within GoldenGate.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with bigdata platforms such as Hadoop or Apache Spark. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala.
However, to harness the full potential of Snowflake’s performance capabilities, it is essential to adopt strategies tailored explicitly for data vault modeling. By implementing the best practices and strategies outlined in this blog, organizations can unlock the full potential of their data vault architecture in Snowflake.
The integration capabilities of KNIME and the scalable data warehousing of Snowflake combine to offer a flexible and powerful platform for financial data analytics. In this blog, we will delve into three specific use cases where the KNIME-Snowflake combination is effectively deployed in the financial services industry.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? One challenge in applying data science is to identify pertinent business issues.
The first generation of data architectures represented by enterprise datawarehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
However, not all of it is necessarily actionable and some get stuck in queues or bigdata batch processing. Additionally, Apache Flink contextualizes your data by detecting patterns, enabling you to understand how things happen alongside each other.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
By leveraging Snowflake’s cloud-native architecture and the principles of the Data Vault model, organizations can unlock numerous benefits in terms of scalability, performance, data integrity, and collaborative data sharing. What is a Data Vault Architecture? Using dbt is one of the best choices. Contact phData!
Even as we grow in our ability to extract vital information from bigdata, the scientific community still faces roadblocks that pose major data mining challenges. In this article, we will discuss 10 key issues that we face in modern data mining and their possible solutions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content