This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing bigdata.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
If this time 10 years ago you were working in data and analytics, something was about to happen that would go on to dominate a large part of your professional life. I’m talking about the emergence of “bigdata.” The post BigData at 10: Did Bigger Mean Better? appeared first on DATAVERSITY.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While data warehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between DataLakes and Data Warehouses appeared first on DATAVERSITY.
Summary: This blog delves into the multifaceted world of BigData, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Subscribe to Alation's Blog.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. BigData Architect.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. Arghya Banerjee is a Sr.
In the ever-evolving landscape of data management, two key concepts have emerged as essential components for organizations seeking to harness the power of their data: data marts and datalakes. Understanding the distinctions […]
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? It can also be integrated into major data platforms like Snowflake.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Managing, storing, and processing data is critical to business efficiency and success. Modern data warehousing technology can handle all data forms. Significant developments in bigdata, cloud computing, and advanced analytics created the demand for the modern data warehouse.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI. How does an open data lakehouse architecture support AI? All of this supports the use of AI.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. This blog post has demonstrated how AWS can greatly benefit your SaaS company, on multiple levels. Conclusions.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Known for his thought leadership in the realm of BigData and advanced analytics, James specializes in contemporary data architectures including the modern data warehouse, data lakehouse, data fabric, and data mesh. James Serra discusses data lakehouses, which merge datalakes and data warehouses.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
A lot of people in our audience are looking at implementing datalakes or are in the middle of bigdatalake initiatives. I know in February of 2017 Munich Re launched their own innovative platform as a cornerstone for analytics that involved a bigdatalake and a data catalog.
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of bigdata and self-service analytics.
This blog was originally written by Keith Smith and updated for 2023 by Nick Goble & Dominick Rocco. You’ve probably heard of the Snowflake Data Cloud , but did you know that Snowflake also offers a revolutionary set of libraries and runtimes called Snowpark? What is Snowflake’s Snowpark? This can be a major optimization.
With high-speed file transfer, integrated services and cross-region offerings, IBM Cloud Object Storage allows you to leverage your data securely. In addition, it helps to reduce backup costs, provide permanent access to archived data, store data for cloud-native applications and create datalakes for bigdata analytics and AI.
You can use the advanced search and filter option in SageMaker Canvas to select columns that are of String data type to simplify the process. Refer to the SageMaker Canvas blog for other examples using SageMaker Data Wrangler. He has a background in AI/ML & bigdata.
We live in an era of bigdata. Amazingly, statistics show that around 90 percent of this data is only two years old. However, Data Management and structuring are notoriously complex. […]. The post The Need for Flexible Data Management: Why Is Data Flexibility So Important?
Esra Kayabalı is a Senior Solutions Architect at AWS, specialized in the analytics domain, including data warehousing, datalakes, bigdata analytics, batch and real-time data streaming, and data integration. She has worked on commercial, supply chain, and discovery-related projects.
The amount of data generated in the digital world is increasing by the minute! This massive amount of data is termed “bigdata.” We may classify the data as structured, unstructured, or semi-structured. Data that is structured or semi-structured is relatively easy to store, process, and analyze. […].
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with bigdata platforms such as Hadoop or Apache Spark. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data.
In entered the BigData space in 2013 and continues to explore that area. Arghya is focused on BigData, DataLakes, Streaming, Batch Analytics and AI/ML services and technologies. He also holds an MBA from Colorado State University. Arghya Banerjee is a Sr.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. What is Apache NiFi?
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Prior joining AWS, as a Data/Solution Architect he implemented many projects in BigData domain, including several datalakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
Esra Kayabalı is a Senior Solutions Architect at AWS, specializing in the analytics domain including data warehousing, datalakes, bigdata analytics, batch and real-time data streaming and data integration. He loves combining open-source projects with cloud services.
With this integration, customers can now harness the full power of Azure’s BigData offerings in a self-service manner to gain immediate value.”. This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance.
In an earlier blog, I defined a data catalog as “a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.”.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























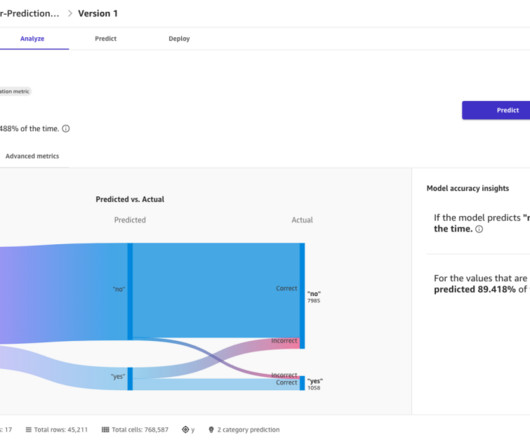









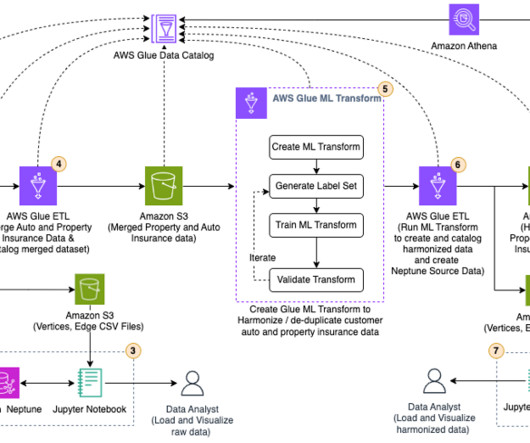
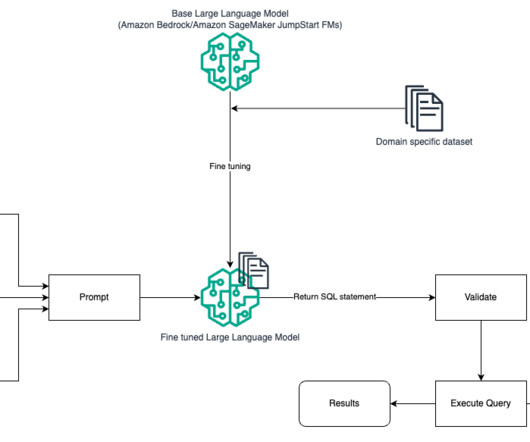


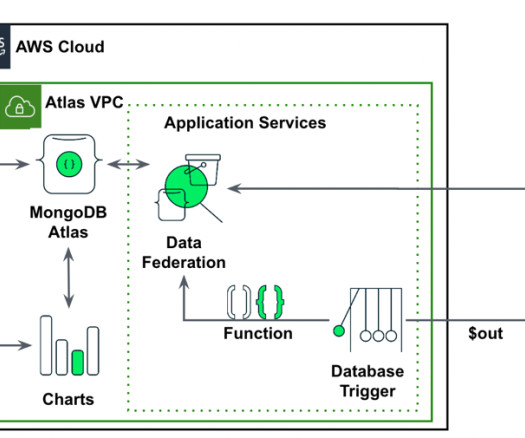








Let's personalize your content