This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing bigdata.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
Text analytics is crucial for sentiment analysis, content categorization, and identifying emerging trends. Bigdataanalytics: Bigdataanalytics is designed to handle massive volumes of data from various sources, including structured and unstructured data.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
With SageMaker, datascientists and developers can quickly and effortlessly build and train ML models, and then directly deploy them into a production-ready hosted environment. She joined Getir in 2022, and has been working as a DataScientist. SageMaker is a fully managed ML service.
She then joined Getir in 2022 as a datascientist and has worked on Recommendation Engine projects, Mathematical Programming for Workforce Planning. Emre Uzel received his Master’s Degree in Data Science from Koç University. Emre Uzel received his Master’s Degree in Data Science from Koç University.
She worked as a datascientist at Arcelik, focusing on spare-part recommendation models and age, gender, emotion analysis from speech data. She then joined Getir in 2022 as a Senior DataScientist working on forecasting and search engine projects. He joined Getir in 2021, and has been working as a DataScientist.
To make this easier, businesses must create an organized data storage and retrieval system. Storage tools like data warehouses and datalakes will help efficiently store the data, streamlining both retrieval and analysis. The analysis helps to identify patterns and trends that can provide actionable insights.
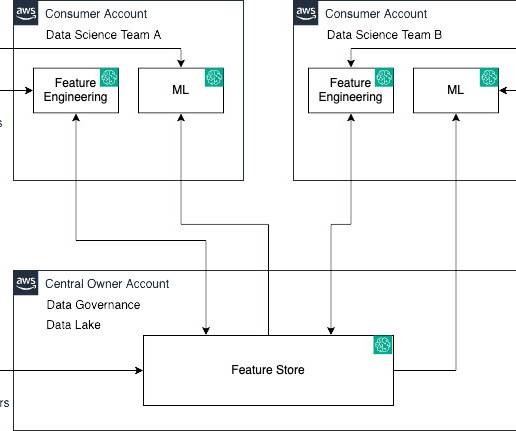
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Datascientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
Additionally, students should grasp the significance of BigData in various sectors, including healthcare, finance, retail, and social media. Understanding the implications of BigDataanalytics on business strategies and decision-making processes is also vital.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Data Warehousing concepts and knowledge should be strong.
Thus, making it easier for analysts and datascientists to leverage their SQL skills for BigData analysis. It applies the data structure during querying rather than data ingestion. Thus ensuring optimal performance. Schema-on-Read Unlike traditional databases, Hive follows a schema-on-read approach.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




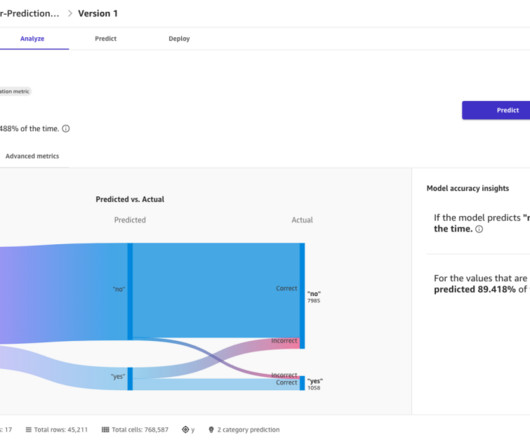




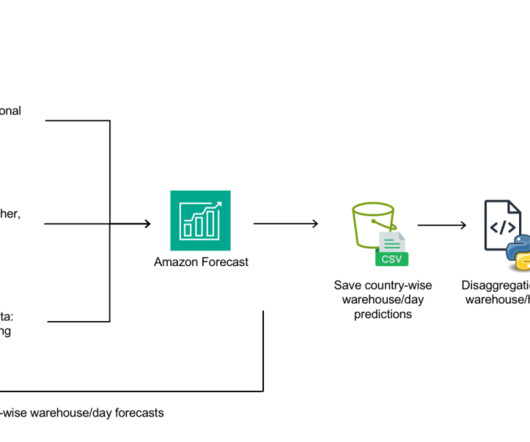
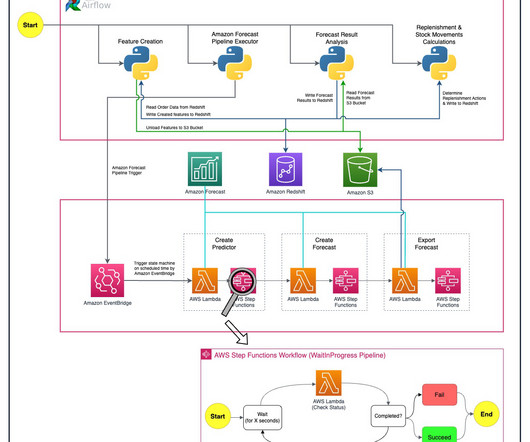









Let's personalize your content