This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations must become skilled in navigating vast amounts of data to extract valuable insights and make data-driven decisions in the era of bigdataanalytics. Amidst the buzz surrounding bigdata technologies, one thing remains constant: the use of Relational Database Management Systems (RDBMS).
The data in Amazon Redshift is transactionally consistent and updates are automatically and continuously propagated. Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization.
The data collected in the system may in the form of unstructured, semi-structured, or structured data. This data is then processed, transformed, and consumed to make it easier for users to access it through SQL clients, spreadsheets and Business Intelligence tools.
It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). It offers extensibility and integration with various data engineering tools.
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
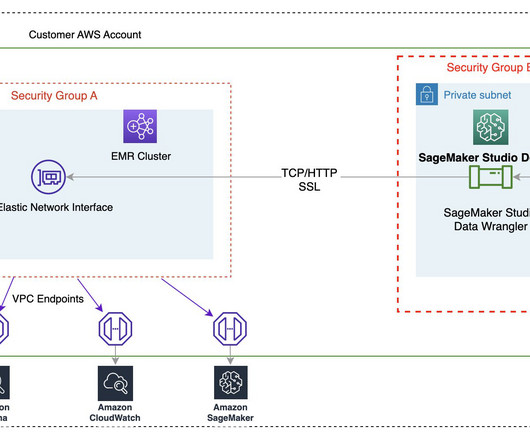
Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints.
There are a lot of important queries that you need to run as a data scientist. This tool can be great for handing SQL queries and other data queries. Every data scientist needs to understand the benefits that this technology offers. Users can slice up cube data using a variety of metrics, filters, and dimensions.
Data professionals such as data scientists want to use the power of Apache Spark , Hive , and Presto running on Amazon EMR for fast data preparation; however, the learning curve is steep. The outputs of this template are as follows: An S3 bucket for the data lake. An EMR cluster with EMR runtime roles enabled.
Here are some of the key advantages of Hadoop in the context of bigdata: Scalability: Hadoop provides a scalable solution for bigdata processing. It allows organizations to store and process massive amounts of data across a cluster of commodity hardware.
Hive is a data warehousing infrastructure built on top of Hadoop. It has the following features: It facilitates querying, summarizing, and analyzing large datasets Hadoop also provides a SQL-like language called HiveQL Hive allows users to write queries to extract valuable insights from structured and semi-structured data stored in Hadoop.
Additionally, students should grasp the significance of BigData in various sectors, including healthcare, finance, retail, and social media. Understanding the implications of BigDataanalytics on business strategies and decision-making processes is also vital.
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
Speed Kafka’s data processing system uses APIs in a unique way that help it to optimize data integration to many other database storage designs, such as the popular SQL and NoSQL architectures , used for bigdataanalytics.
Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigDataAnalytics market, valued at $307.51 Turning raw data into meaningful insights helps businesses anticipate trends, understand consumer behaviour, and remain competitive in a rapidly changing world.
They store structured data in a format that facilitates easy access and analysis. Data Lakes: These store raw, unprocessed data in its original format. They are useful for bigdataanalytics where flexibility is needed. These tools work together to facilitate efficient data management and analysis processes.
In a new SQL cell, enter the following SELECT statement to view the content of the table SELECT * FROM rmscatalog.salesdb.store_sales Throughout this example, we demonstrated how to create a table in Amazon Redshift Serverless and seamlessly query it as an Iceberg table using Apache Spark within a SageMaker Unified Studio notebook.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigDataanalytics provides a competitive advantage and drives innovation across various industries.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content