This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? Schema-based sharding has almost no datamodelling restrictions or special steps compared to unsharded PostgreSQL.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
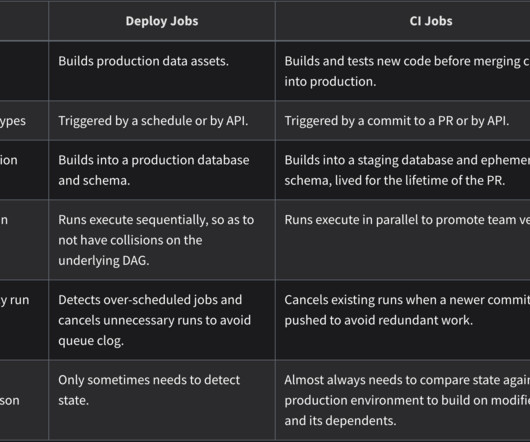
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Why did something break?
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. diagram Using ChatGPT to build system diagrams — Part II Generate C4 diagrams using mermaid.js
It is a process for moving and managing data from various sources to a central data warehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
Sidebar Navigation: Provides a catalog sidebar for browsing resources by type, package, file tree, or database schema, reflecting the structure of both dbt projects and the data platform. Version Tracking: Displays version information for models, indicating whether they are prerelease, latest, or outdated.
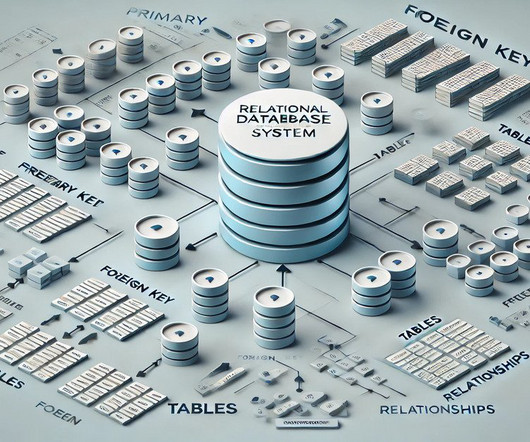
DataModel : RDBMS relies on a structured schema with predefined relationships among tables, whereas NoSQL databases use flexible datamodels (e.g., key-value pairs, document-based) that accommodate unstructured data. Scalability : RDBMS typically scales vertically by adding more resources to a single server.
You should test the entire ML model development chain, for example: Data collection: Test the quality, accuracy, and relevance of the data collected to ensure it meets the needs of the model. Feature creation: Validate and test the processes used to select, manipulate, and transform data.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Mikiko Bazeley: You definitely got the details correct. I definitely don’t think I’m an influencer. It will store the features (including definitions and values) and then serve them. It’s almost like a very specialized data storage solution. For example, you can use BigQuery , AWS , or Azure.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content