This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
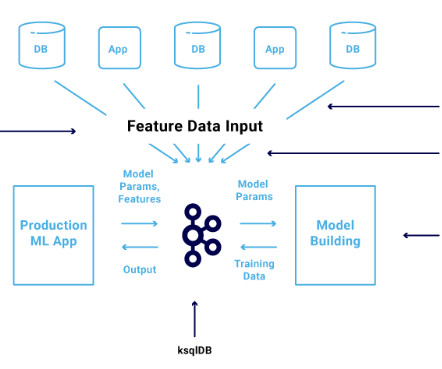
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Welcome to this comprehensive guide on Azure Machine Learning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machine learning models. Sit back, relax, and enjoy this exploration of Azure Machine Learning’s capabilities, benefits, and practical applications.
Summary: This blog provides a comprehensive roadmap for aspiring AzureDataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
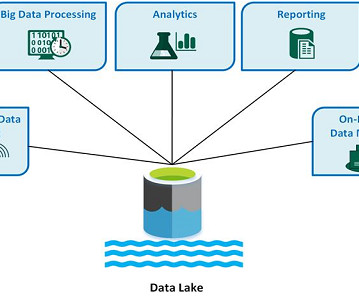
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
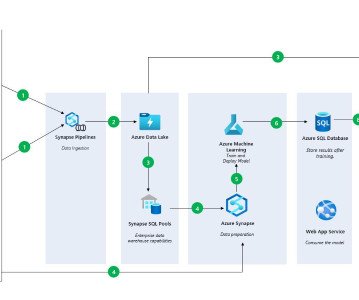
Azure Synapse. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and AzureDataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure Machine Learning. Azure Quantum.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Accordingly, one of the most demanding roles is that of AzureData Engineer Jobs that you might be interested in. The following blog will help you know about the AzureData Engineering Job Description, salary, and certification course. How to Become an AzureData Engineer?
Organizations that want to prove the value of AI by developing, deploying, and managing machine learning models at scale can now do so quickly using the DataRobot AI Platform on Microsoft Azure. DataRobot is available on Azure as an AI Platform Single-Tenant SaaS, eliminating the time and cost of an on-premises implementation.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Enjoy significant Azure connectivity improvements to better optimize Tableau and Azure together for analytics. This offers everyone from datascientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI.
Additionally, Azure Machine Learning enables the operationalization and management of large language models, providing a robust platform for developing and deploying AI solutions. Strategic Collaboration with OpenAI Microsoft’s partnership with OpenAI is one of the most significant in the AI industry.
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. However, these tools have functional gaps for more advanced data workflows.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. They are often built by datascientists who are not software engineers or computer science majors by training. Data Science Layers. Software Architecture.
This crucial step involves handling missing values, correcting errors (addressing Veracity issues from Big Data), transforming data into a usable format, and structuring it for analysis. This often takes up a significant chunk of a datascientist’s time. It turns the raw ocean of data into actionable intelligence.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Data integration: Integrate data from various sources into a centralized cloud data warehouse or datalake. Ensure that data is clean, consistent, and up-to-date. Use ETL (Extract, Transform, Load) processes or data integration tools to streamline data ingestion.
Delphina Demo: AI-powered DataScientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai In this demo, you’ll see how Delphina’s AI-powered “junior” datascientist can transform the data science workflow, automating labor-intensive tasks like data discovery, transformation, and model building.
Enjoy significant Azure connectivity improvements to better optimize Tableau and Azure together for analytics. This offers everyone from datascientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
In this upcoming livestream interview, we’ll chat with Adam Ross Nelson, data science career coach, about the skills needed to get a job in AI and what steps you can do today to hit your career goals. In addition, we’ll discuss a variety of tools that form the modern LLM application development stack.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
From October 29th to 31st, we’ve curated a schedule packed with over 150 hands-on workshops and expert-led talks designed to help you sharpen your skills and elevate your role as a datascientist or AI professional. Industry, Opinion, Career Advice AI for Robotics and Autonomy with Francis X.
We’re empowering datascientists, ML engineers, and other builders with new capabilities that make generative AI development faster, easier, more secure, and less costly. In fact, 96 percent of all AI/ML unicorns—and 90 percent of the 2024 Forbes AI 50—are AWS customers. Baskar earned a Ph.D.
This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. While there’s a need for analyzing smaller datasets on your laptop, expanding into TB+ datasets requires a whole new set of skills and data analytics frameworks.
At the AI Expo and Demo Hall as part of ODSC West in a few weeks, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Microsoft Azure, Hewlett Packard, Iguazio, neo4j, Tangent Works, Qwak, Cloudera, and others.
This functionality provides access to data by storing it in an open format, increasing flexibility for data exploration and ML modeling used by datascientists, facilitating governed data use of unstructured data, improving collaboration, and reducing data silos with simplified datalake integration.
If you are a datascientist, manager, or executive with limited time and funds, wondering whether/how to invest in data centers and what the pros, cons, and costs would be, chances are you will start from a similar place as I — having some knowledge then looking for more, be that from humans, machines, or both.
Jupyter notebooks have been one of the most controversial tools in the data science community. Nevertheless, many datascientists will agree that they can be really valuable – if used well. Data on its own is not sufficient for a cohesive story. There are some outspoken critics , as well as passionate fans.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The Cloud Data Migration Challenge. Support for languages and SQL. Model Drift.
Thus, making it easier for analysts and datascientists to leverage their SQL skills for Big Data analysis. It applies the data structure during querying rather than data ingestion. Processing of Data Once the data is stored, Hive provides a metadata layer allowing users to define the schema and create tables.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Use Multiple Data Models With on-premise data warehouses, storing multiple copies of data can be too expensive.
ETL pipeline | Source: Author These activities involve extracting data from one system, transforming it, and then processing it into another target system where it can be stored and managed. ML heavily relies on ETL pipelines as the accuracy and effectiveness of a model are directly impacted by the quality of the training data.
Customer centricity requires modernized data and IT infrastructures. Too often, companies manage data in spreadsheets or individual databases. This means that you’re likely missing valuable insights that could be gleaned from datalakes and data analytics. 75% faster onboarding of analysts and datascientists.
Both persistent staging and datalakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer data pipeline. With Snowflake’s support for Iceberg: You can query Iceberg tables stored in your cloud storage (S3, Azure Blob, etc.)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content