This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
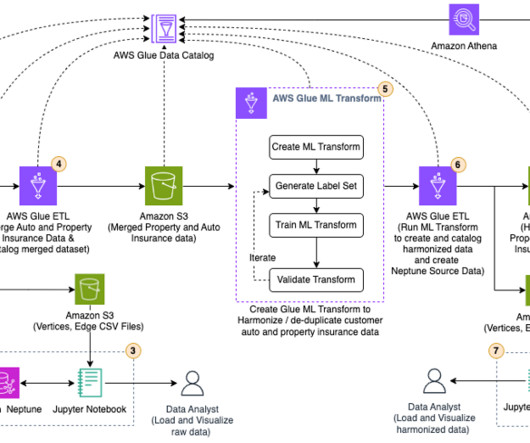
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
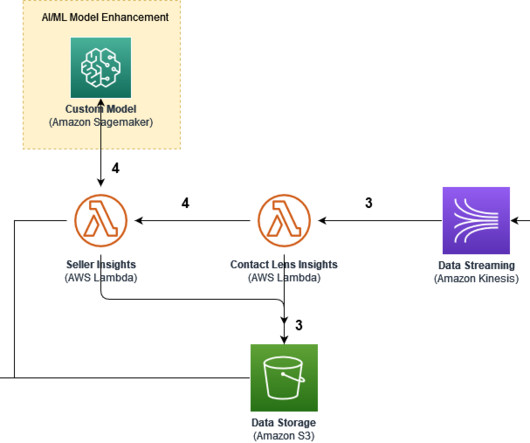
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications. Demand for applied ML scientists remains high, as more companies focus on AI-driven solutions for scalability.
Machine learning (ML) is the technology that automates tasks and provides insights. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It features an ML package with machine learning-specific APIs that enable the easy creation of ML models, training, and deployment.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. We also deep dive into the most common architectures and AWS resources to facilitate these integrations.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
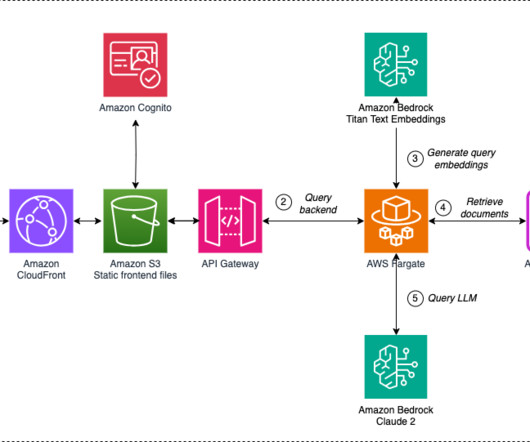
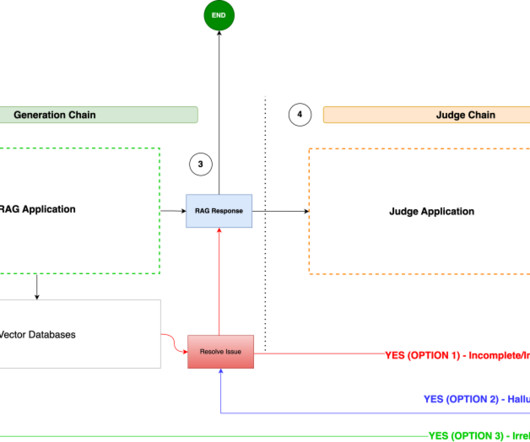
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. First, it can be time consuming for users to learn multiple services development experiences.
ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. Model developers often work together in developing ML models and require a robust MLOps platform to work in.
AI credits from Confluent can be used to implement real-time data pipelines, monitor data flows, and run stream-based ML applications. Amazon Web Services(AWS) AWS offers one of the most extensive AI and ML infrastructures in the world. Modal Modal offers serverless compute tailored for data-intensive workloads.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This use case, solvable through ML, can enable support teams to better understand customer needs and optimize response strategies.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
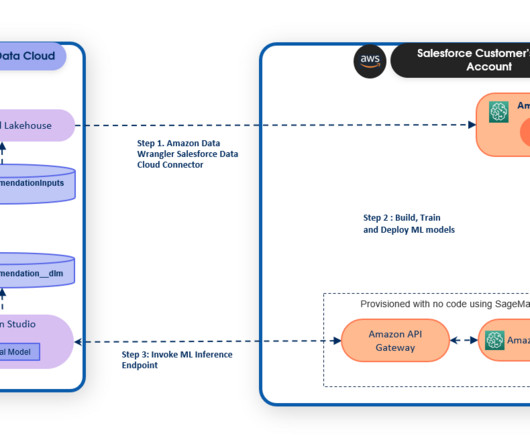
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
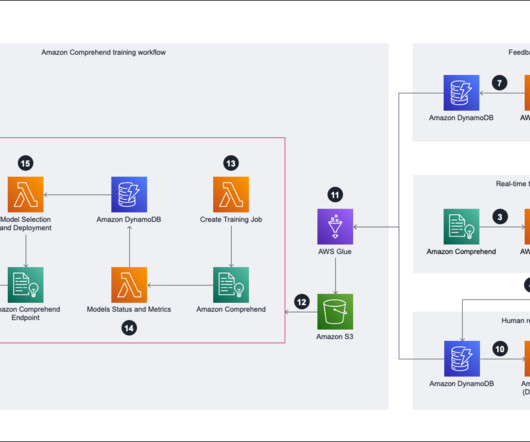
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
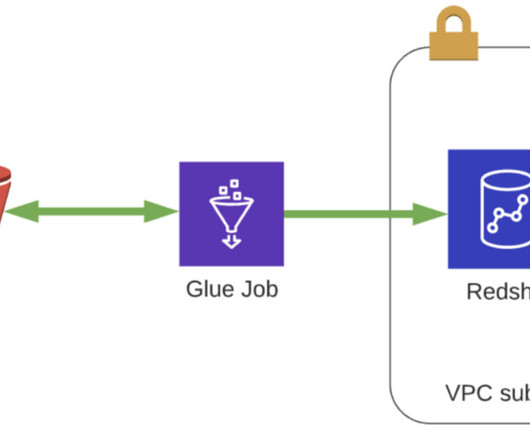
In this article, we will discover how to build an ETL pipeline by consuming data from S3 to AWS Redshift via the Glue service and… Continue reading on MLearning.ai »
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. SageMaker integration SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. or later image versions.
The key requirement for TR’s new machine learning (ML)-based personalization engine was centered around an accurate recommendation system that takes into account recent customer trends. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker.
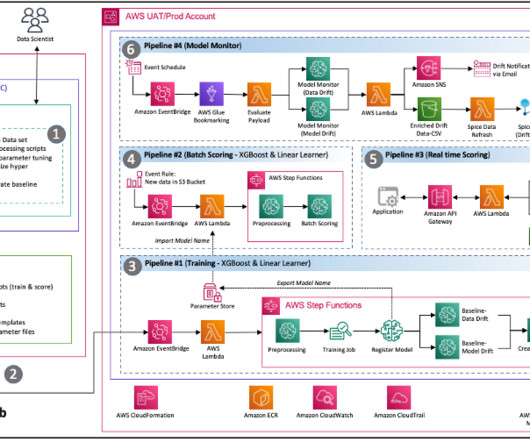
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
Generative AI empowers organizations to combine their data with the power of machine learning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. As with all other industries, the energy sector is impacted by the generative AI paradigm shift, unlocking opportunities for innovation and efficiency.
By segment, North America revenue increased 12% Y oY from $316B to $353B, International revenue grew 11% Y oY from$118B to $131B, and AWS revenue increased 13% Y oY from $80B to $91B. The template is compatible with and can be modified for other LLMs, such as LLMs hosted on Amazon Sagemaker Jumpstart and self-hosted on AWS infrastructure.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage. Processing jobs also support Pipe mode.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. An example would be AWS recognition.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content