This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
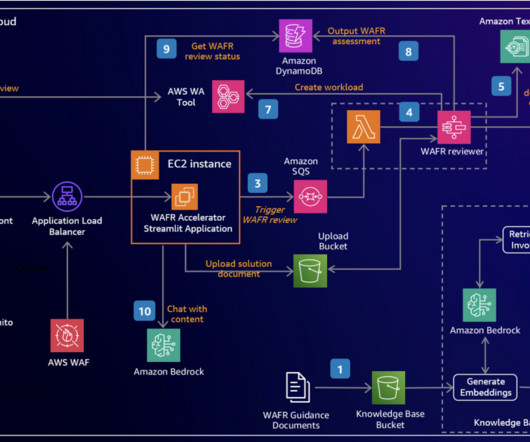
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
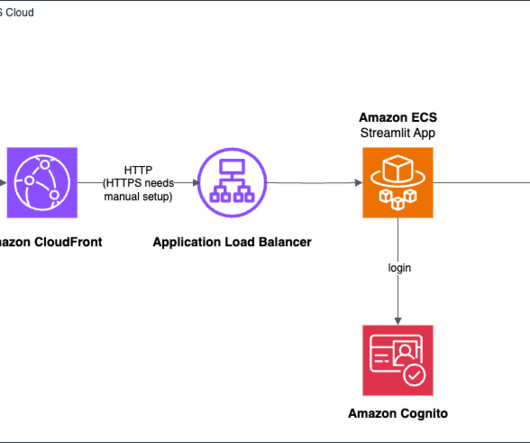
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. For example, you can give users access permission to download popular packages and customize the development environment.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
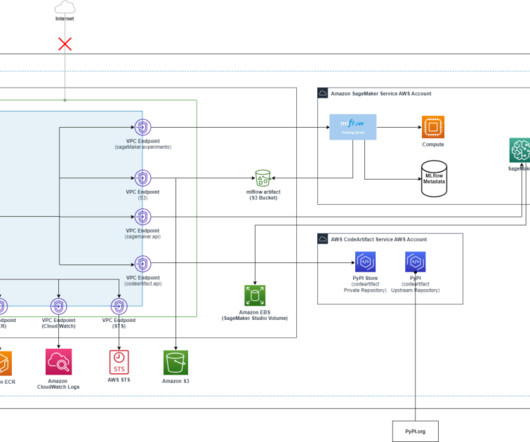
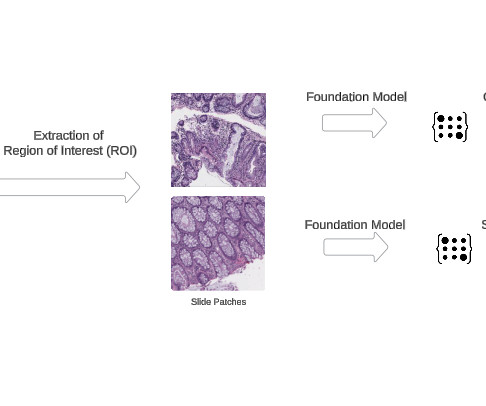
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
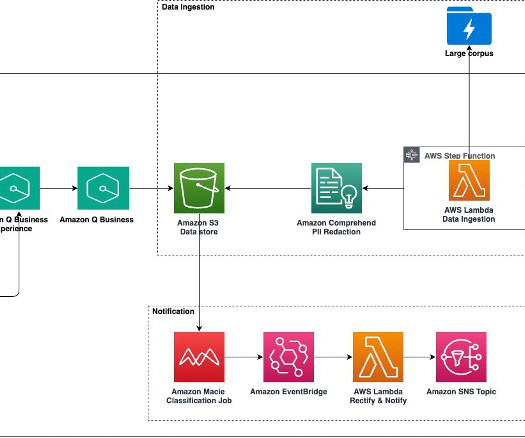
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
In this post, we explore how to use the power of AWS Resilience Hub and Amazon Bedrock to bridge this gap and streamline the process of sharing architectural findings across your organization. Prerequisites For this walkthrough, the following are required: An AWS account. AWS Management Console access. A Python 3.12 environment.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
AWS has always provided customers with choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
This post is co-authored by Manuel Lopez Roldan, SiMa.ai, and Jason Westra, AWS Senior Solutions Architect. Prerequisites Before you get started, make sure you have the following: An AWS account. If you dont have an AWS account, you can create one. The AWS Command Line Interface (AWS CLI), Docker, and Git installed locally.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
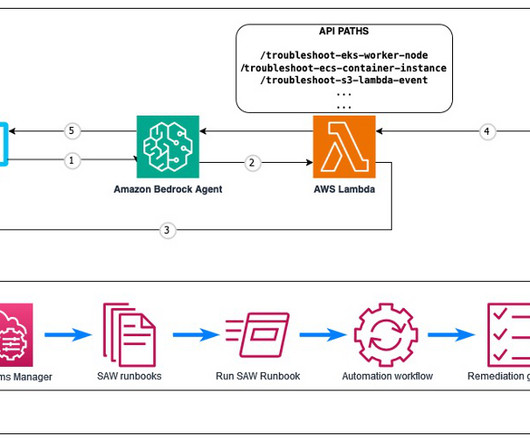
As AWS environments grow in complexity, troubleshooting issues with resources can become a daunting task. Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows , which is a collection of curated AWS Systems Manager self-service automation runbooks. The agent uses Anthropics Claude 3.5
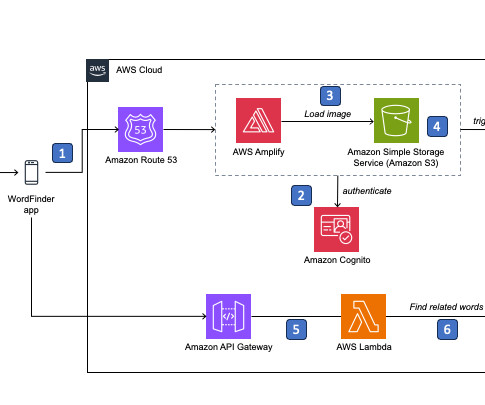
David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology. The following diagram illustrates the solution architecture on AWS.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3. S3 […] The post Top 6 Amazon S3 Interview Questions appeared first on Analytics Vidhya.
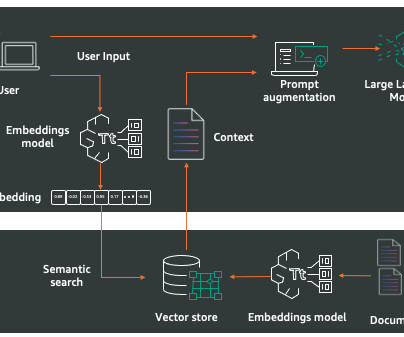
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
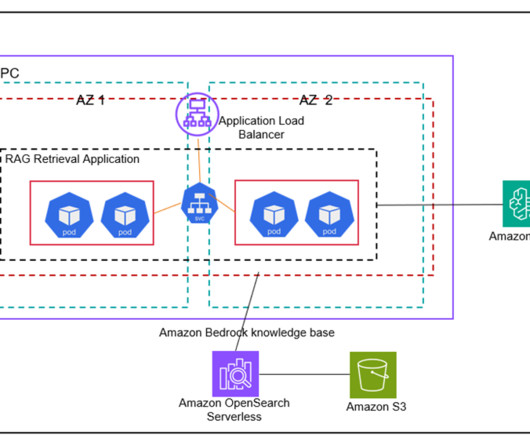
In this post, we demonstrate a solution using Amazon Elastic Kubernetes Service (EKS) with Amazon Bedrock to build scalable and containerized RAG solutions for your generative AI applications on AWS while bringing your unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way. Sonnet on Amazon Bedrock.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. This workflow integrates AWS services to extract, process, and make content available for querying.
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. For this walkthrough, we will use the AWS CLI to trigger the processing.
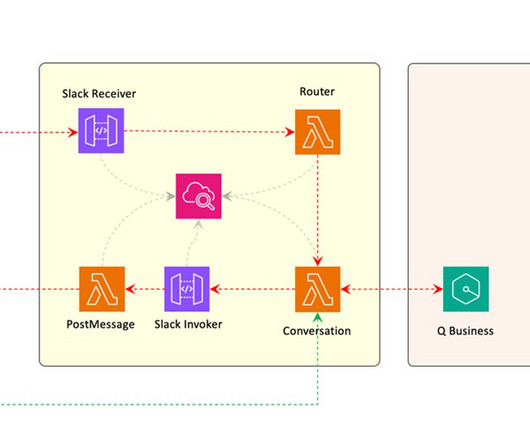
In this post, we show you how to integrate the popular Slack messaging service with AWS generative AI services to build a natural language assistant where business users can ask questions of an unstructured dataset. In this solution, we have enabled the AWS provided profanity filter.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
However, by using various AWS services, you can quickly deploy a serverless solution to edit images. Amazon Bedrock is serverless, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
AWS Lambda – A compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Because services such as Amazon S3 and Amazon SNS can directly trigger an AWS Lambda function, you can build a variety of real-time serverless data-processing systems.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up.
Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. To reduce the time it takes to download and load the container image, SageMaker now supports container caching.
Amazon Q Business uses AWS IAM Identity Center to record the workforce users you assign access to and their attributes, such as group associations. IAM Identity Center is used by many AWS managed applications such as Amazon Q. Why use trusted identity propagation? Promotes software design principles rooted in user privacy.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. An AWS account. Install AWS Command Line Interface (AWS CLI) and use aws configure to set up your IAM credentials securely.
Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS.
Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. In this post, we demonstrate how easy it is to deploy Llama 3 on AWS Trainium and AWS Inferentia based instances in SageMaker JumpStart.
Prerequisites Make sure you meet the following prerequisites: Make sure your SageMaker AWS Identity and Access Management (IAM) role has the AmazonSageMakerFullAccess permission policy attached. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe.
In this post, we use the multi-agent feature of Amazon Bedrock to demonstrate a powerful and innovative approach to AWS cost management. By using the advanced capabilities of Amazon Nova FMs, weve developed a solution that showcases how AI-driven agents can revolutionize the way organizations analyze, optimize, and manage their AWS costs.
Today, AWS AI released GraphStorm v0.4. Prerequisites To run this example, you will need an AWS account, an Amazon SageMaker Studio domain, and the necessary permissions to run BYOC SageMaker jobs. Using SageMaker Pipelines to train models provides several benefits, like reduced costs, auditability, and lineage tracking. million edges.
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Open the AWS Management Console, go to Amazon Bedrock, and choose Model access in the navigation pane.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors. Starting with PyTorch 2.3.1,
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content