This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
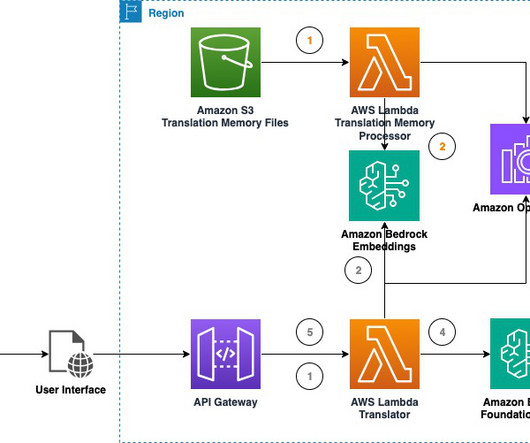
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
Between monitoring, analyzing, and documenting architectural findings, a lack of crucial information can leave your organization vulnerable to potential risks and inefficiencies. Prerequisites For this walkthrough, the following are required: An AWS account. AWS Management Console access. A Python 3.12 environment.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
Creating professional AWS architecture diagrams is a fundamental task for solutions architects, developers, and technical teams. These diagrams serve as essential communication tools for stakeholders, documentation of compliance requirements, and blueprints for implementation teams.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. The SageMaker Core SDK comes bundled as part of the SageMaker Python SDK version 2.231.0
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
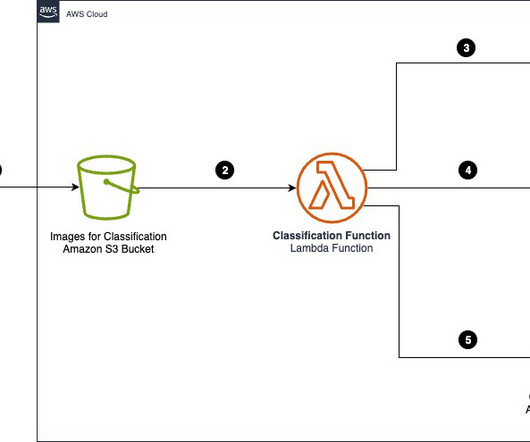
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. This personalized document helps the customer gain a deeper understanding of the vehicle and supports their decision-making process.
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. The higher-level abstracted layer is designed for data scientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
In this post, we show you how to integrate the popular Slack messaging service with AWS generative AI services to build a natural language assistant where business users can ask questions of an unstructured dataset. In this example, we ingest the documentation of the Amazon Well-Architected Framework into the knowledge base.
This new capability from Amazon Bedrock offers a unified experience for developers of all skillsets to easily automate the extraction, transformation, and generation of relevant insights from documents, images, audio, and videos to build generative AI powered applications.
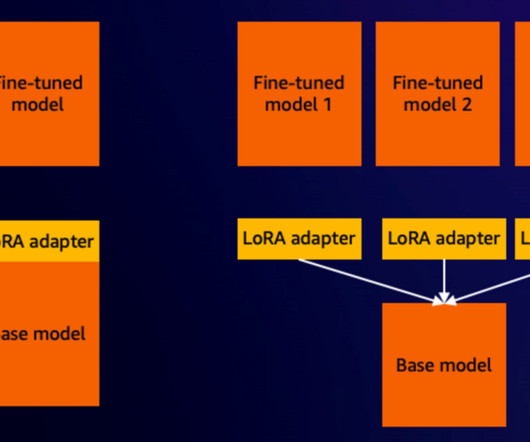
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Formalizing and documenting this invaluable resource can help organizations maintain institutional memory, drive innovation, enhance decision-making processes, and accelerate onboarding for new employees. However, effectively capturing and documenting this knowledge presents significant challenges.
AWS has always provided customers with choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
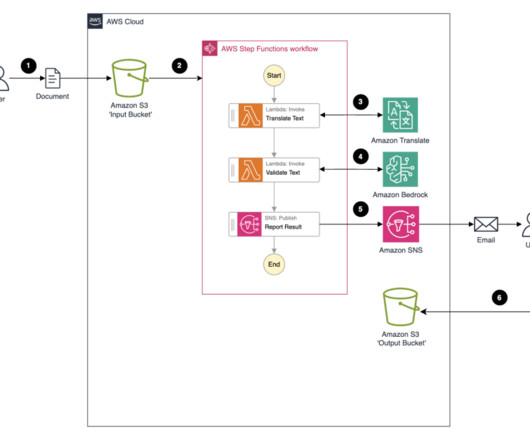
Maintaining consistency and alignment across these global operations can be difficult, especially when it comes to updating and sharing business documents and processes. In this post, we show how you can automate language localization through translating documents using Amazon Web Services (AWS).
The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security. Discover the Medical LLM – Small model in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK.
For this example, we enter the following: You are an expert financial analyst with years of experience in summarizing complex financial documents. For this post, we use the following prompt: Summarize the following financial document for {{company_name}} with ticker symbol {{ticker_symbol}}: Please provide a brief summary that includes 1.
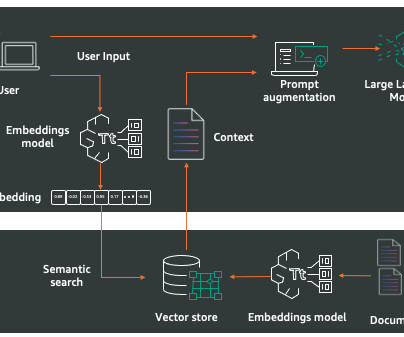
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
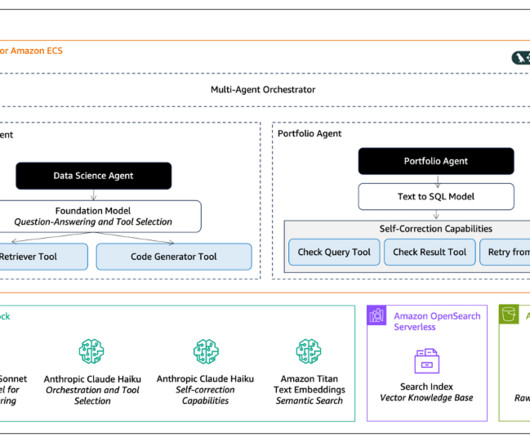
It aims to boost team efficiency by answering complex technical queries across the machine learning operations (MLOps) lifecycle, drawing from a comprehensive knowledge base that includes environment documentation, AI and data science expertise, and Python code generation. Its also adept at troubleshooting coding errors.
In Part 1 of this series, we introduced the newly launched ModelTrainer class on the Amazon SageMaker Python SDK and its benefits, and showed you how to fine-tune a Meta Llama 3.1 Shweta Singh is a Senior Product Manager in the Amazon SageMaker Machine Learning (ML) platform team at AWS, leading SageMaker Python SDK.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. However, some components may incur additional usage-based costs.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
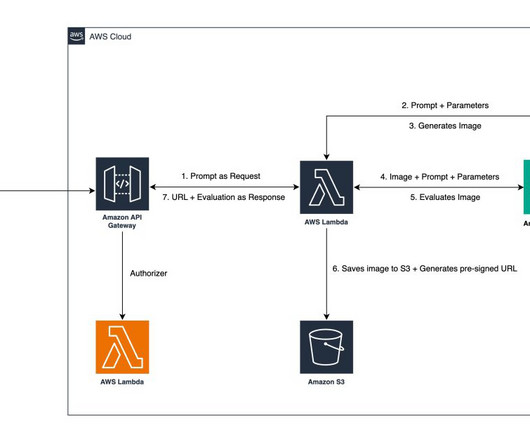
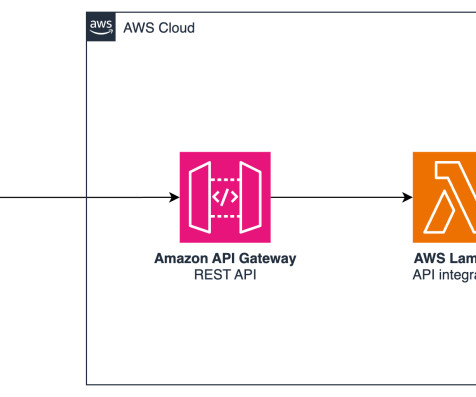
Solution overview This solution is running in AWS Region us-east-1. It exposes an API endpoint through Amazon API Gateway that proxies the initial prompt request to a Python-based AWS Lambda function, which calls Amazon Bedrock twice. In this post, we will review the console, the terminal, and AWS CLI. Anthropic Claude 3.5
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
This new cutting-edge image generation model, which was trained on Amazon SageMaker HyperPod , empowers AWS customers to generate high-quality images from text descriptions with unprecedented ease, flexibility, and creative potential. Large model is available today in the following AWS Regions: US East (N. By adding Stable Diffusion 3.5
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. Improving document retrieval results helps personalize the responses generated for each user.
This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance. Amazon Titan Embeddings also integrates smoothly with AWS, simplifying tasks like indexing, search, and retrieval.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
For this post, we run the code in a Jupyter notebook within VS Code and use Python. Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. We walk through a Python example in this post.
At Amazon Web Services (AWS), we recognize that many of our customers rely on the familiar Microsoft Office suite of applications, including Word, Excel, and Outlook, as the backbone of their daily workflows. Using AWS, organizations can host and serve Office Add-ins for users worldwide with minimal infrastructure overhead.
Introducing Amazon Bedrock Agents and Powertools for AWS Lambda To address these challenges, we can leverage two powerful tools that work seamlessly together: Amazon Bedrock Agents utilize functional calling to invoke AWS Lambda functions with embedded business logic. User: Does AWS have any recent FedRAMP compliance documents?
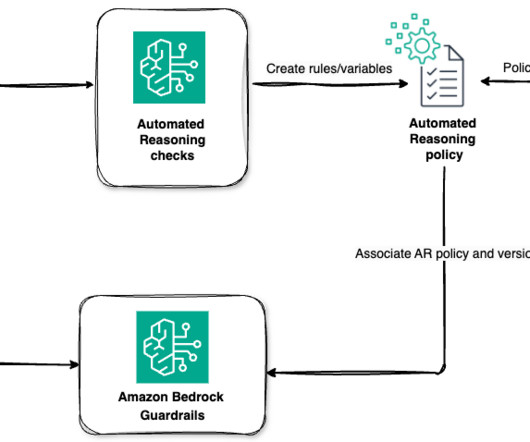
To improve factual accuracy of large language model (LLM) responses, AWS announced Amazon Bedrock Automated Reasoning checks (in gated preview) at AWS re:Invent 2024. For example, AWS customers have direct access to automated reasoning-based features such as IAM Access Analyzer , S3 Block Public Access , or VPC Reachability Analyzer.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
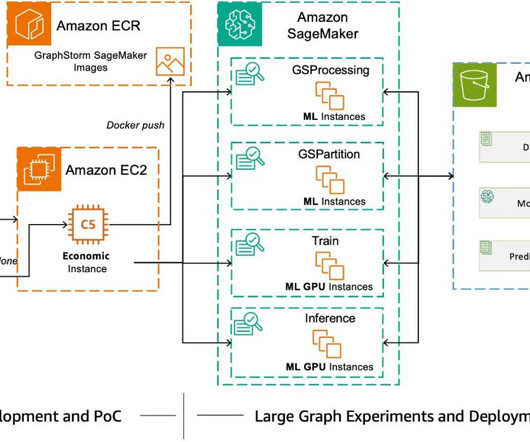
Today, AWS AI released GraphStorm v0.4. Prerequisites To run this example, you will need an AWS account, an Amazon SageMaker Studio domain, and the necessary permissions to run BYOC SageMaker jobs. Using SageMaker Pipelines to train models provides several benefits, like reduced costs, auditability, and lineage tracking. million edges.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content